

Hi, I'm Michael. I'm a UI engineer at HashiCorp.

HashiCorp is a cloud infrastructure automation company.


The product I work on is Nomad.

Nomad is a cluster scheduler, or container orchestrator. It helps you easily deploy applications at any scale.

This isn't a Nomad talk so I'll keep this short, but it helps to know what we're building a UI for. Within Nomad, there are lots of things going on all the time. Most action is coming from the cluster itself, but users still want to stay informed. We can't wait on user action to update the state of the world.
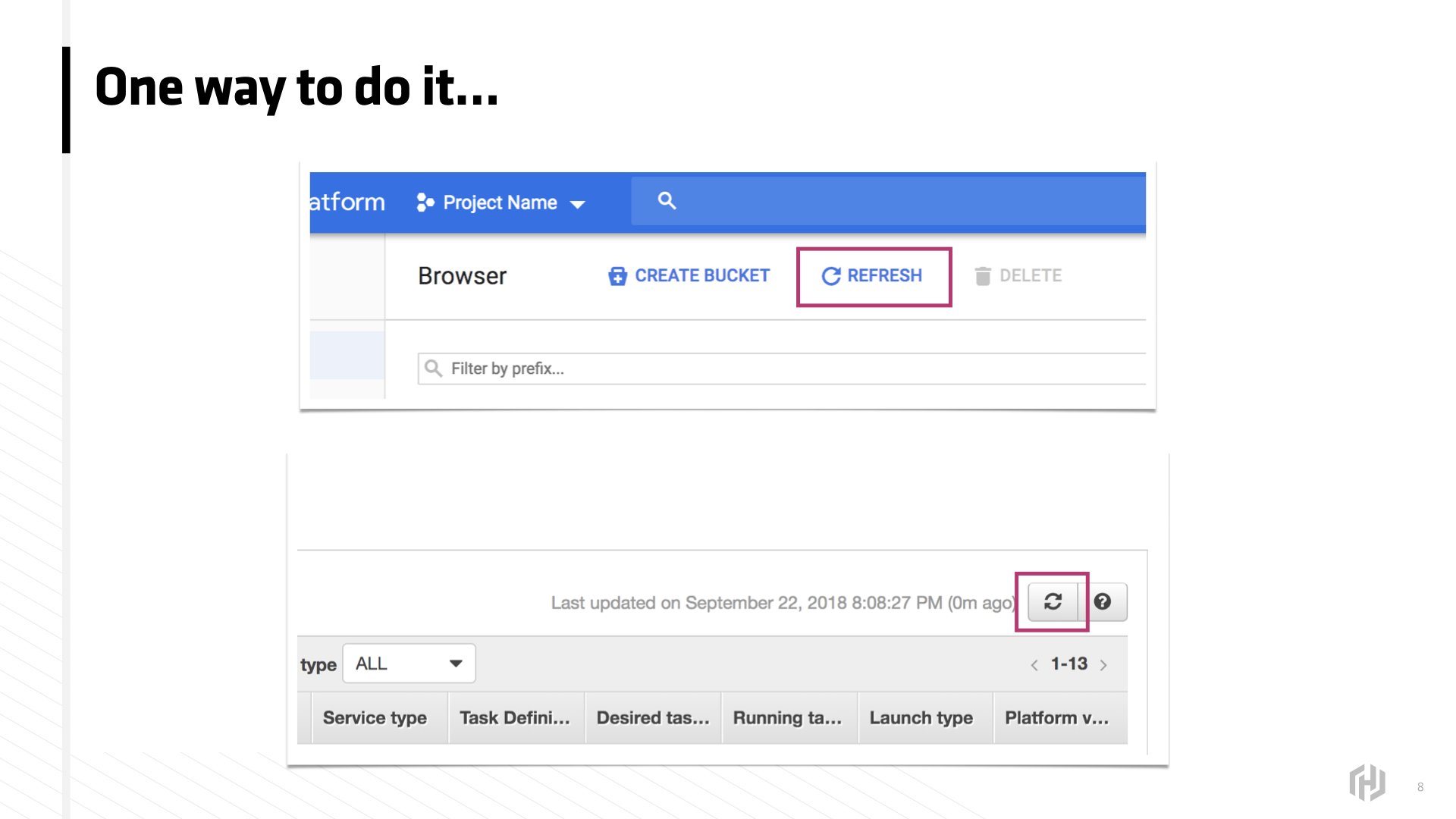
One way to do this is to add a refresh button, but that's kind of clunky. Furthermore, it's dated. The seams are starting to show between the people who build websites and those who use websites. Any casual web user can look at this refresh button and have a simple questions.

Can't it just do that automatically? Twitter telle me about new tweets. My email clients pushes notifications. Lyft will at least attempt to show me where my ride is. And Spotify will tell me what my friends are listening to even though I never asked for that and I have never cared.
So why doesn't your web app do that?

Everything nodel and great eventually becomes commodity. Great becomes standard. Standard becomes dated.

So. Let's go realtime.

This is exactly what we set out to do. Over the course of a month or so in early 2018, I made the Nomad UI realtime, and this is my story.

First I want to warn you, this talk isn't going to end in an ember install. This is a use case
talk that only directly applies to the Nomad UI. However, I think the lessons learned along the way
are broadly applicable.

Implementing this functionality was a five step progress.
- Understand the API
- Break down the problem
- Make it work for one page
- Find the right abstractions
- Celebrate
First, let's look at the API.

Nomad uses a feature called Blocking Queries
to support realtime data fetching. It's an implementation of long-polling that uses an index query
param on any supported URL to invoke. When invoked, the request may block depending on the current
index value for the request. Each URL maintains a monotonic index, which is sent in every request as
the value for the X-Nomad-Index header.

In this first example, /job/job-1, the request will immediately resolve because there is no
index query parameter.
In the second example, /job/job-1?index=1, the request will still immediately resolve because the
index query parameter value is behind the current index for the URL.
In the third example, /job/job-1?index=10, the request will remain open (block) until the index
for the URL increments (e.g., job is stopped server-side).
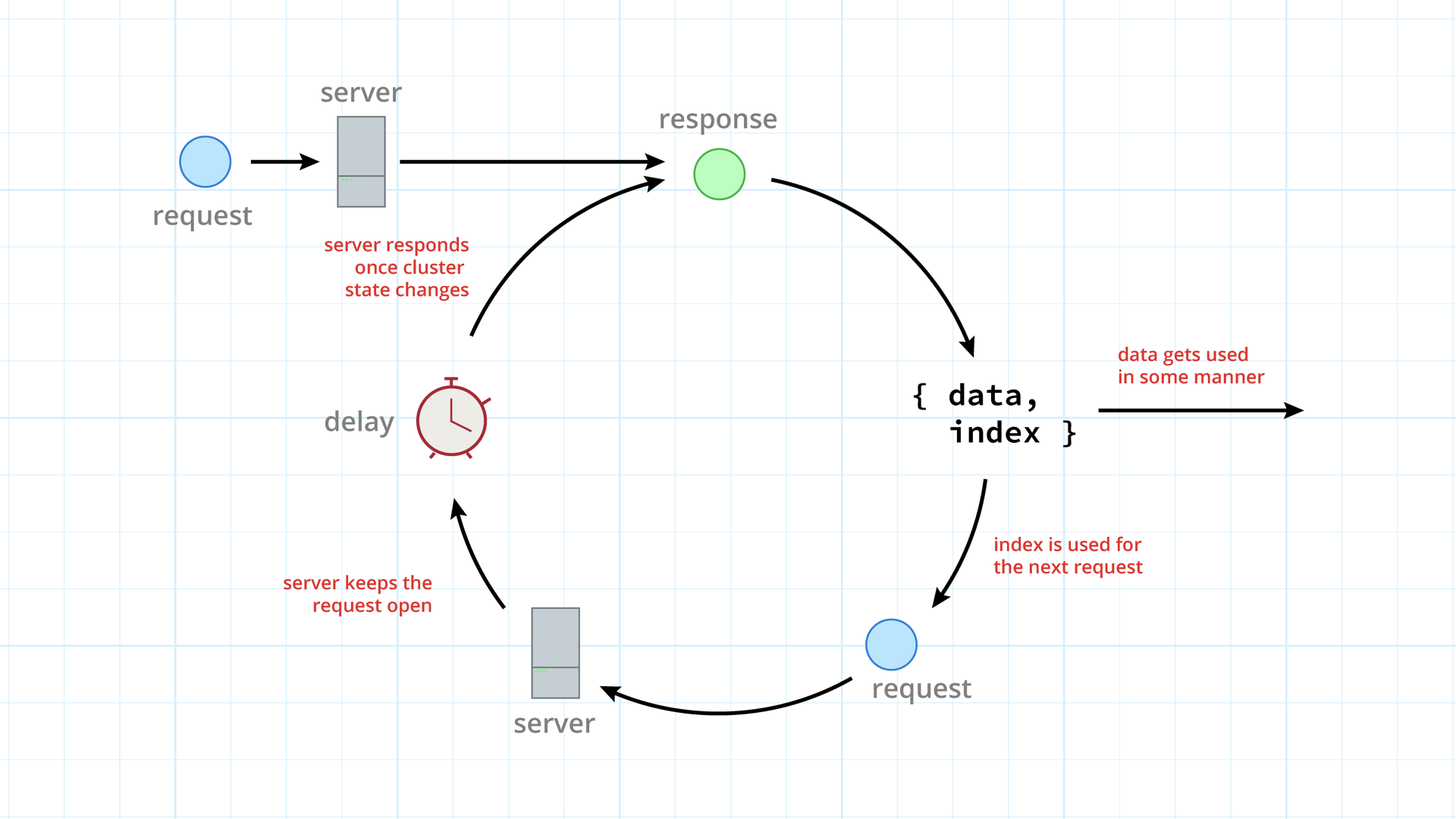
So with those details in mind, we can imagine a blocking query request loop. Where first an initial
request is made, from the response we extract the index value from the X-Nomad-Index header, do
whatever we want with the data, immediately make a new request for the same data with the index
query parameter this time, eventually get a response from that request, and then start the process
all over.

At this point you might be thinking this is all very odd.

Why not use WebSockets? Isn't it meant for this?

If you're hip on all the tools we have available to us you might be thinking this is a job for ServerSentEvents and EventSource.

Or, the one that is tossed around all too often, "Why not just change the API?"

The short answer is the API already exists. APIs can't always be changed on a whim for the benefit of the UI. Plus this API pre-dates the UI. Plus this API works just fine.

In fact it's actually really good. It's a low-tech solution that can be used in a variety of tools,
ranging from cURL to Ember. It's entirely stateless, unlike WebSockets which relies on long-lived
connections. This is critical for Nomad since it's designed to withstand complete server failure.
It's also naturally fault tolerant. In the event that a connection is lost for whatever reason,
there is no state to rehydrate, or event listeners to reattach. You just make the same request
again.

So that's the API. Now we have to somehow integrate this with an Ember app. Let's break down the problem.

We need to implement long-polling (since that's what Blocking Queries is), then we have to update all the pages in the app to use long-polling, and finally we need to re-render all the things when long-polls resolve with new data.

Since there's always that guy on Hacker News (and it's always a guy) who likes to invalidate other people's hard work by writing a half-baked alternative in bash, I decided to get ahead of the story and do that myself.
Here is long-polling in bash. It's less than 30 lines including comments.
# Starting index
idx="1"
while true
do
# Append index as a query param
url="http://localhost:4646/v1/job/example?index=$idx"
echo -e "\nCurling $url..."
curl -i -s $url | grep -v "^" > polltmp
while read -r line
do
# Use the X-Nomad-Index header to set the new index
key="$(echo $line | cut -d ':' -f 1)"
val="$(echo $line | cut -d ':' -f 2 | tr -d '[:space:]')"
if [ "$key" = "X-Nomad-Index" ]
then
idx="$val"
fi
done < polltmp
# Do stuff with the payload
tail -1 polltmp | jq ". | {Name, Status, ModifyIndex}"
done
First we set a starting index (idx) of 1, since this is the lowest possible index value.
# Starting indexidx="1"while true
do
# Append index as a query param
url="http://localhost:4646/v1/job/example?index=$idx"
echo -e "\nCurling $url..."
curl -i -s $url | grep -v "^" > polltmp
while read -r line
do
# Use the X-Nomad-Index header to set the new index
key="$(echo $line | cut -d ':' -f 1)"
val="$(echo $line | cut -d ':' -f 2 | tr -d '[:space:]')"
if [ "$key" = "X-Nomad-Index" ]
then
idx="$val"
fi
done < polltmp
# Do stuff with the payload
tail -1 polltmp | jq ". | {Name, Status, ModifyIndex}"
done
Then, in an infinite loop, construct a URL using this index value and fetch it with cURL.
# Starting index
idx="1"
while true
do
# Append index as a query param url="http://localhost:4646/v1/job/example?index=$idx" echo -e "\nCurling $url..." curl -i -s $url | grep -v "^" > polltmp while read -r line
do
# Use the X-Nomad-Index header to set the new index
key="$(echo $line | cut -d ':' -f 1)"
val="$(echo $line | cut -d ':' -f 2 | tr -d '[:space:]')"
if [ "$key" = "X-Nomad-Index" ]
then
idx="$val"
fi
done < polltmp
# Do stuff with the payload
tail -1 polltmp | jq ". | {Name, Status, ModifyIndex}"
done
After we get a response, we then loop over the headers looking for the header named X-Nomad-Token.
We set idx to the value of this header. It represents the new current server-side index value.
# Starting index
idx="1"
while true
do
# Append index as a query param
url="http://localhost:4646/v1/job/example?index=$idx"
echo -e "\nCurling $url..."
curl -i -s $url | grep -v "^" > polltmp
while read -r line
do
# Use the X-Nomad-Index header to set the new index key="$(echo $line | cut -d ':' -f 1)" val="$(echo $line | cut -d ':' -f 2 | tr -d '[:space:]')" if [ "$key" = "X-Nomad-Index" ] then idx="$val" fi done < polltmp
# Do stuff with the payload
tail -1 polltmp | jq ". | {Name, Status, ModifyIndex}"
done
Finally, we do stuff with the data. In this example jq is used to filter the JSON response. And
then the cycle repeats since this is all in an infinite loop.
The live presentation includes a demonstration of this code.
# Starting index
idx="1"
while true
do
# Append index as a query param
url="http://localhost:4646/v1/job/example?index=$idx"
echo -e "\nCurling $url..."
curl -i -s $url | grep -v "^" > polltmp
while read -r line
do
# Use the X-Nomad-Index header to set the new index
key="$(echo $line | cut -d ':' -f 1)"
val="$(echo $line | cut -d ':' -f 2 | tr -d '[:space:]')"
if [ "$key" = "X-Nomad-Index" ]
then
idx="$val"
fi
done < polltmp
# Do stuff with the payload tail -1 polltmp | jq ". | {Name, Status, ModifyIndex}"done
So there you have it. It works. We must be done. Not quite, I'd say. Whenever I'm writing any code, I have this internal checklist where I
- Make it work: Code has to do what it's supposed to, first and foremost.
- Make it nice: There are many ways to solve problems, but some solutions are better than others.
- Make it fast: You should avoid premature optimization, but sometimes code is too slow and needs to be changed to be faster.

Making code work is generally straight-forward. It might be a doozy of a problem you are working on, but at least you know what you are working towards. Similarly making something fast is straight-forward. Even if the process of optimizing is challenging, benchmarks will tell you if you are doing better or worse.
It's this "Make it nice" box that ends up being the hardest to check. Nice is subjective.

We like to consider our work to be purely logical where every decision is black and white, but that's frankly not true. There are many ways to write code that performs the same function. Each with different squishy tradeoffs.
We have all experienced code we didn't like, we have probably all written that code we didn't like. We also throw out terms like "this code smells bad", or this feels dangerous. These aren't objective critiques, but there is merit to them.
How do you choose the best code? How do you make code that is "nice"?

"Oh, the Places You'll Go!" is an appropriate book to show here in its own right, but I honestly only chose it because of this kids face. That's the expression you make when faced with the paradox of choice for the first time.

But it can be a big choice and it's one that has to be made. If all you ever do is write code that simply works, you're slowly building a house of cards that will eventually collapse under the weight of its own complexity.
"Collapse" is a word that is well-rooted in the physical world, so I think it's worth expanding on what code "collapsing" looks like.

When code collapses under its own complexity, you will be experiencing some of these symptoms.
- Inaccurate project estimates: As code increases in complexity, it becomes less and less understood. The less understood code is, the harder it becomes to accurately estimate how much effort is involved in making changes.
- Fear of certain files or subsystems: It only takes getting burned by a bad estimate or two to become conditioned to fear parts of a code base. We learn where the dragons are hiding, there are bound to be unforeseen consequences.
- Habitual Refactoring: The brave among us may take it upon ourselves to refactor these scary places, but odds are they will fail. It's all too common to think you finally understand a complex system completely only to be surprised halfway in. This leads to incomplete refactoring, or maybe backing out of a refactor and starting again from scratch, or multiple refactors because no interation is quite right.
- Unhappy developers: This work environment sucks, to be blunt. No one likes being asked for an estimate they know won't be accurate. No one likes missing deadlines, or spending afternoons debugging nonsensical cruft.
- Unconfident developers: Even worse than unhappiness, this is the kind of code that can shake confidence. Newer engineers, or even tenured engineers that have their own reasons for feeling vulnerable can easily misplace blame on themselves for not "getting it" rather than blaming the code for being overly complex.

Alright, say you're convinced that this is a bad situation. That complexity is dangerous and compounds. What do you do about it? How do we manage complexity?

The one word answer is abstractions!
This is a word that gets thrown around a lot. There are plenty of definitions for it online, but I'm a visual person, so I came up with a visual metaphor for abstractions.

First, consider Minerva in Her Study, a 17th century masterpiece by local hero Rembrandt. Every detail in this painting is perfect. Every crease in her clothing, the texture of the fur, the candid expression on her face, the harsh lighting that is still somehow warm and soft.

Compare this to Smiley in Open Sans, a composition by yours truly in 2018.
I would never ever say that these are equal. Rembrandt was considered a master among masters, while I'm just dangerous in Photoshop. Not that I needed Photoshop to put text on a white background, but that's neither here nor there. The point I wish to make here is that there is a time and a place for both these compositions.

Minerva in Her Study is 0% abstract. Every single detail is realized and unique. Rembrandt had ultimate control over every color, every brush stroke, and all the little pieces that come together to complete the painting. But in doing so, this work would take 100s of hours to recreate and could only be done by a fellow master painter.
Smiley in Open Sans is 100% abstract. It's rigid. There is no room for free expression, but I challenge you to come up with a simpler composition than three symbols that still results in a nearly universally understood smiling face. And anyone in this room could recreate this work in under 30 seconds.

The moral of the story is there is no one true Goldilocks level of abstraction.

It's entirely situational. Sometimes you are going to want something incredibly abstract. Imagine setting up an e-commerce store: you aren't going to want to write a custom credit card payment processor if you can instead use a library that lets you start accepting payments with a single line of code.
A bank on the other hand is deeply concerned with credit card payments. This would be within their core competencies and they would absolutely not want to abstract away every detail.

Okay, where were we. Right, we made it work.

Except we wrote that in bash, and we're gonna need that in JavaScript, so we haven't even done that. Halfway through the presentation and no boxes checked.
Maybe that other list is more favorable.

Step 3 of 5. Not bad. We have gone over the API, and we have broken down the problem, let's see if we can't implement an end-to-end solution for a single page.

We know that the first thing we need to do is thread this index query param into data requests
some how, so let's stat with the data layer.
Within the adapters layer, we need to include the index query param. We will also want to do this
conditionally, since now all requests are going to be blocking. And this is going to eventually
need to work for all adapters that support blocking queries.
For serializers, we don't need to make any changes; the responses are the same.
For models, we also don't need to make any changes; there is no new state to save for records.
How nice that we only need to touch one part of Ember Data to do this. It's clear that the minds behind Ember Data took the time to think through the right abstractions required to make this code nice.
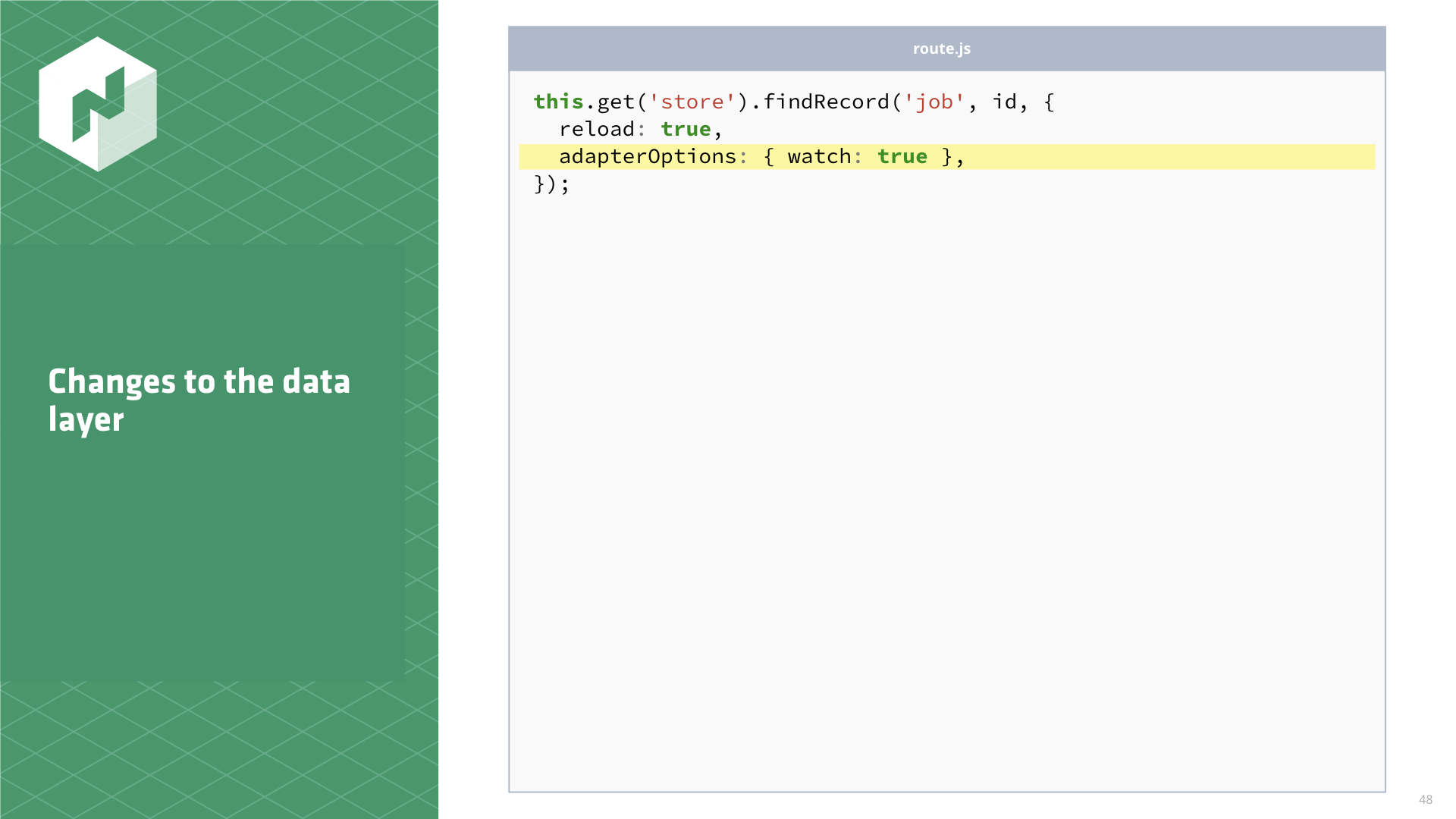
Let's start by getting that optional query parameter into a request somehow. Since it's optional,
we want to add this where we make the request, rather than bury it in the adapter. We can do this
using the Ember Data feature adapterOptions. It's a generic hash of stuff that gets sent to the
adapter for the adapter to decide what to deal with.
I ended up going with watch: true. Notice that we aren't doing anything with the index value here,
just hinting to the adapter that we want to make this request a blocking one.
// route.js
this.get('store').findRecord('job', id, {
reload: true,
adapterOptions: { watch: true },});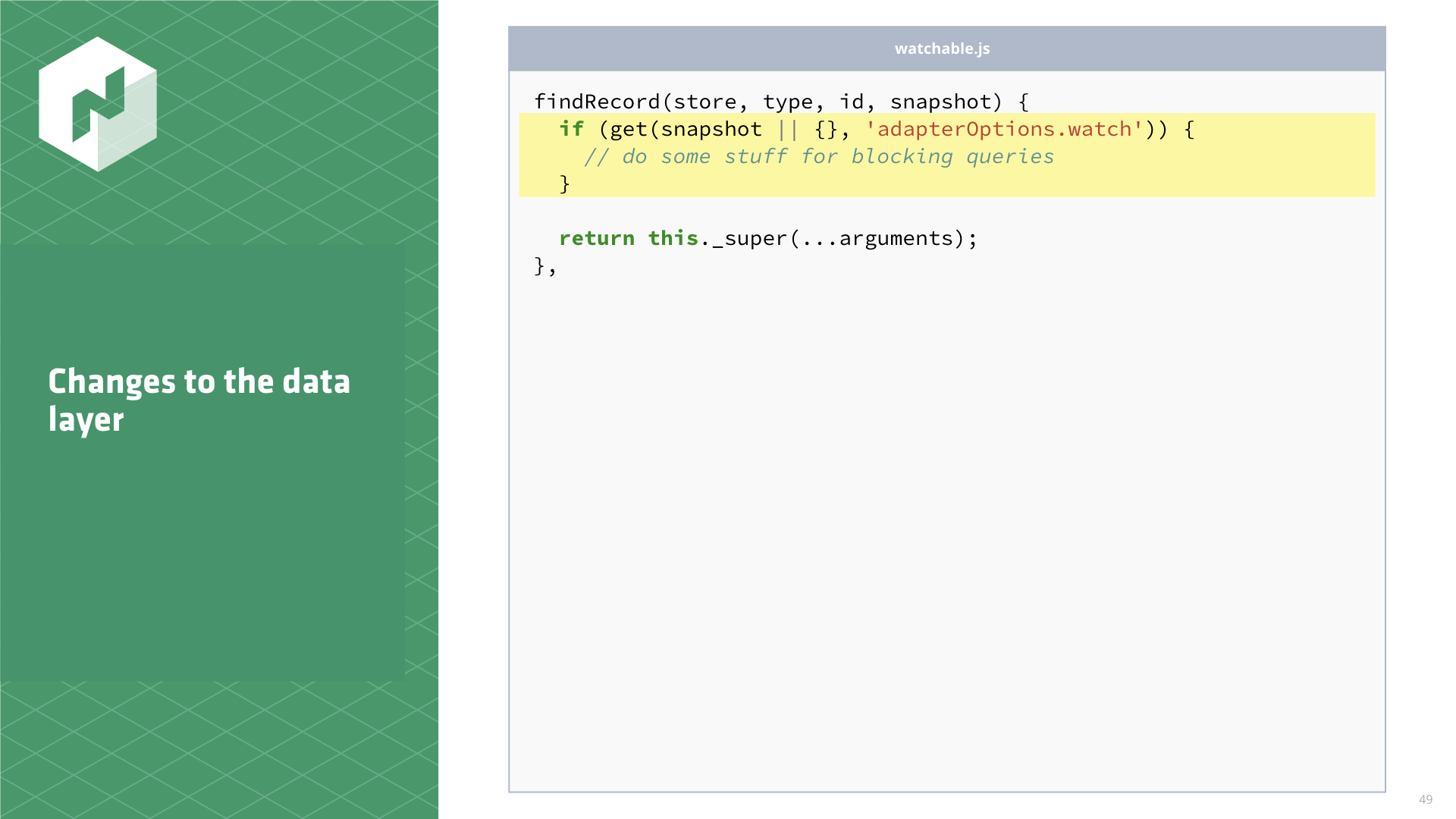
We can start to imagine what the other side of this findRecord call looks like now. Some adapter,
let's call it watchable.js, overrides findRecord, looks for the watch flag, and then does
some blocking query stuff when the flag is set.
// adapters/watchable.js
findRecord(store, type, id, snapshot) {
if (get(snapshot || {}, 'adapterOptions.watch')) { // do some stuff for blocking queries }
return this._super(...arguments);
}
Alright, this looks nice, but there's a glaring open question. How do we track that X-Nomad-Index
value? Where does that state live?
One answer is a WatchList service.
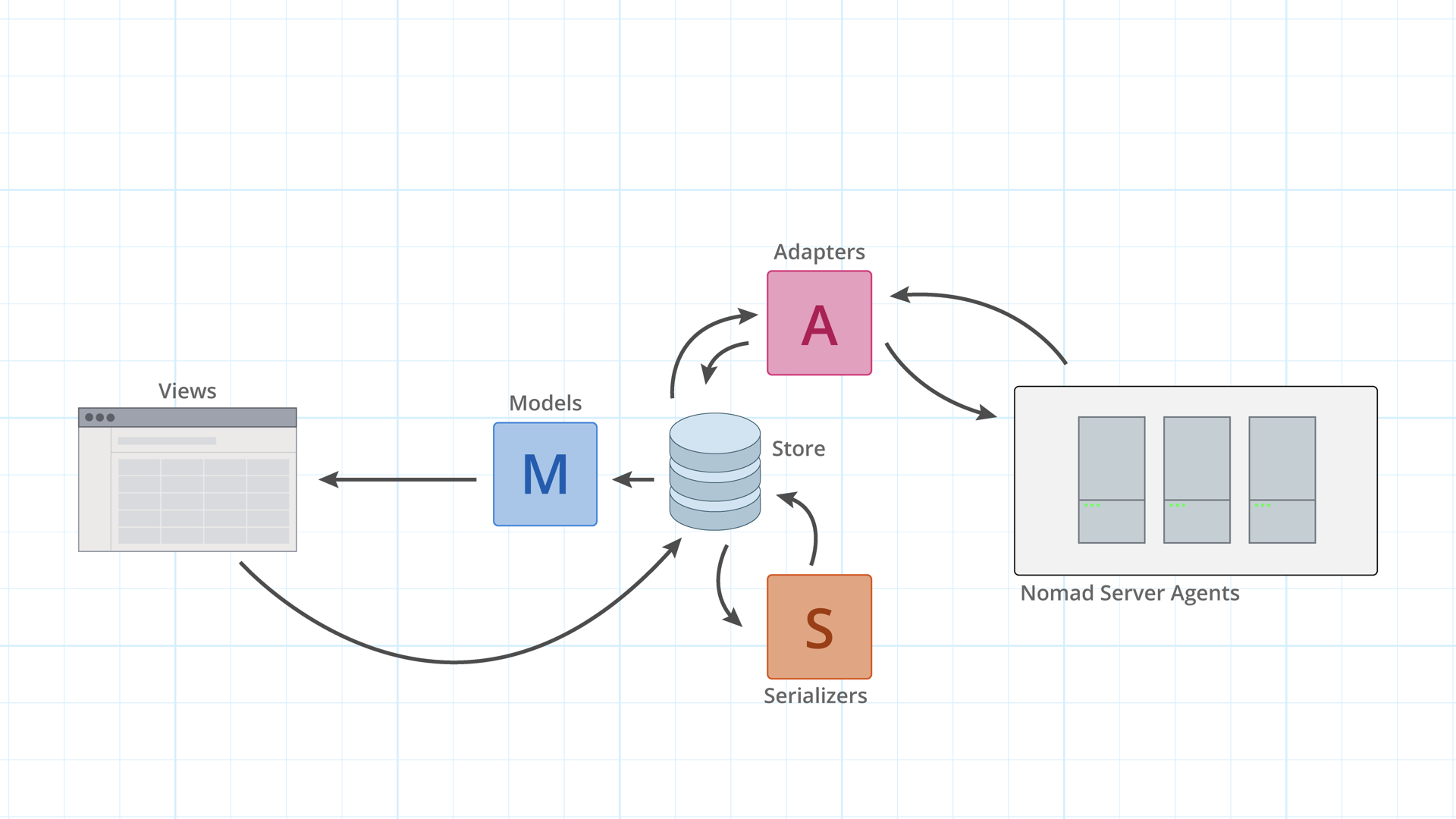
Here's what Ember Data looks like out of the box. Your view-ish-looking code makes a request to the store, the store communicates to the adapter to make a request to the Nomad Server agents, the agents respond with some data, the store passes that data into the corresponding serializer, the serializer returns the normalized version of the response data, the store takes that normalized data and creates/updates/deletes models with it, and finally returns the appropriate models back to your view.
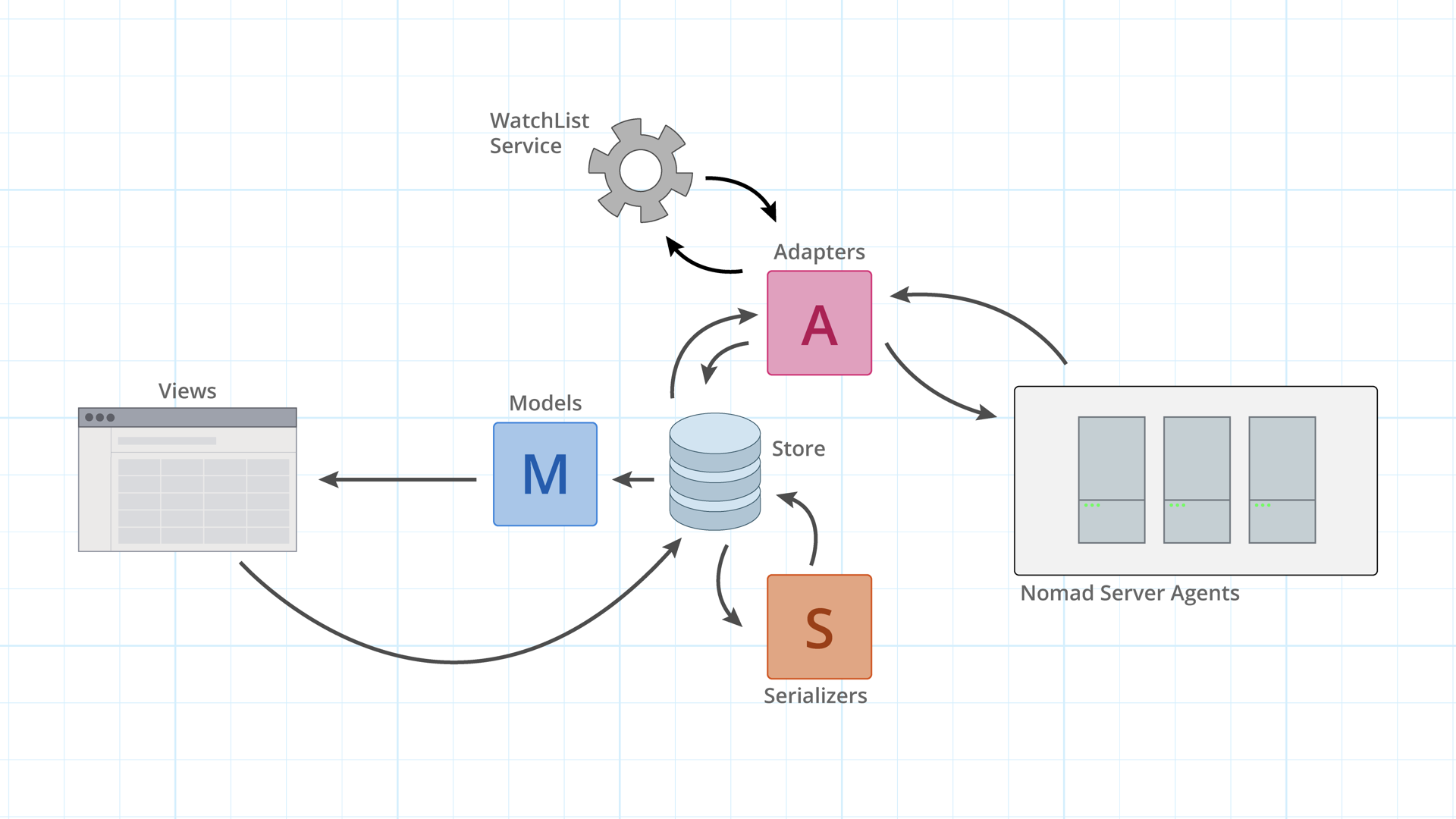
The beautiful thing about Services in Ember is you can just sorta stick them anywhere. In this case, we can stick it up there by the adapter. So now before making a request, the adapter can communicate with this WatchList service to get an index value first.
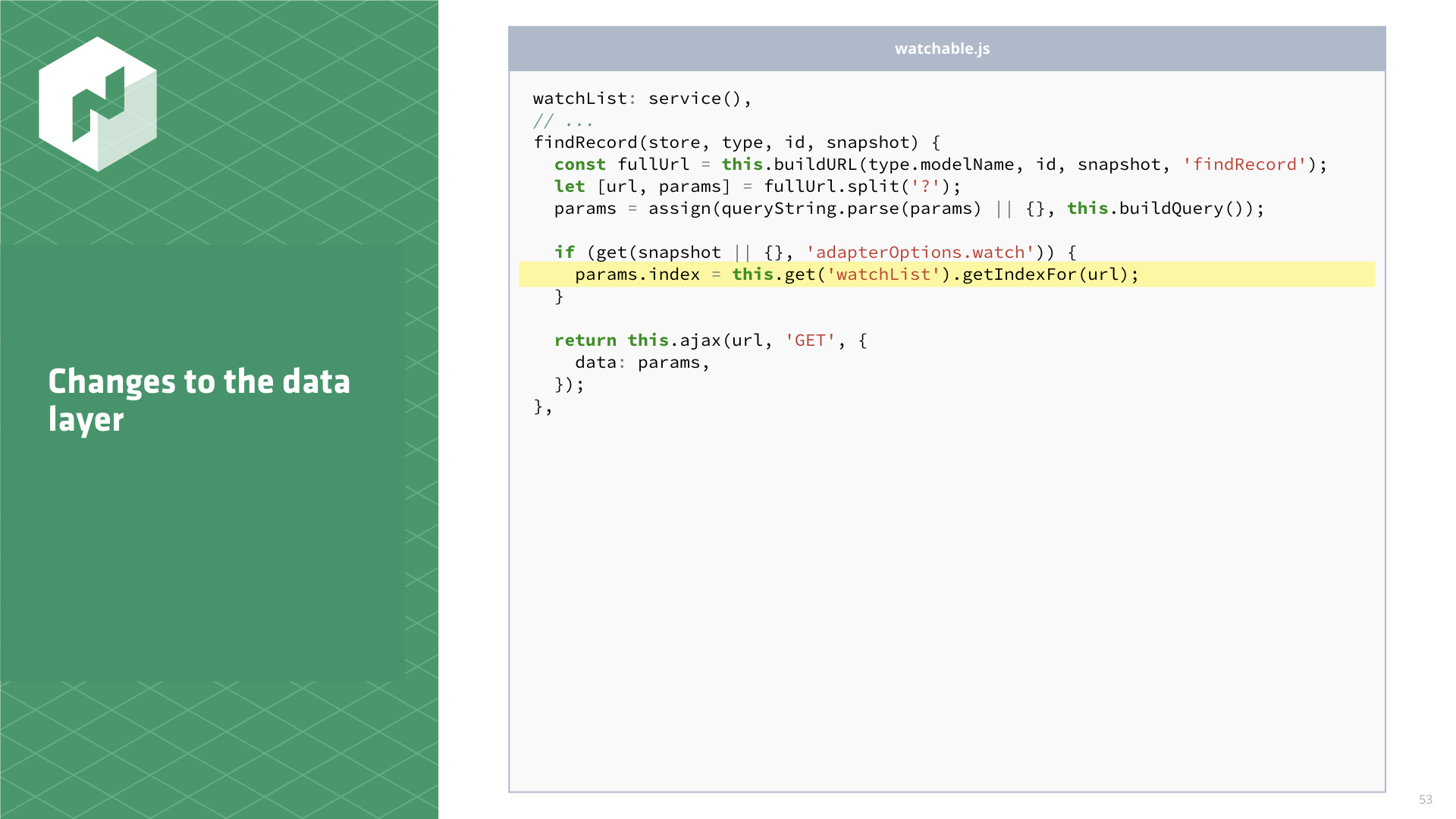
It looks a bit like this.
// adapters/watchable.js
watchList: service(),
// ...
findRecord(store, type, id, snapshot) {
const fullUrl = this.buildURL(type.modelName, id, snapshot, 'findRecord');
let [url, params] = fullUrl.split('?');
params = assign(queryString.parse(params) || {}, this.buildQuery());
if (get(snapshot || {}, 'adapterOptions.watch')) { params.index = this.get('watchList').getIndexFor(url);
}
return this.ajax(url, 'GET', {
data: params,
});
},We can set the index query param to a value we look up on the WatchList using the URL to request
as a key.

We also have to set this index value somewhere. This also happens in the adapter, this time in the
handleResponse method. The handleResponse method is where we have access to the headers, which
is where the new index value is sent.
The setIndexFor method on the WatchList service is straight-forward: it takes a url (a key), and
and index (a value).
// adapters/watchable.js
handleResponse(status, headers, payload, requestData) {
// Some browsers lowercase all headers. Other keep them
// case sensitive.
const newIndex = headers['x-nomad-index'] || headers['X-Nomad-Index'];
if (newIndex) {
this.get('watchList').setIndexFor(requestData.url, newIndex); }
return this._super(...arguments);
}
So that's how the WatchList gets used, but what does the implementation of the WatchList look like? Turns out it's rather unexciting. It's just a mapping of URLs to values with some guarding against accidentally overriding the complete list and some type casting since header values are always strings.
import { readOnly } from '@ember/object/computed';
import { copy } from '@ember/object/internals';
import Service from '@ember/service';
let list = {};
export default Service.extend({
list: readOnly(function() {
return copy(list, true);
}),
init() {
list = {};
},
getIndexFor(url) {
return list[url] || 1;
},
setIndexFor(url, value) {
list[url] = +value;
},
})
At this point, all the Ember Data parts are done. Next we have to change the route to request data in a loopy fashion.
This won't affect the model hook, since we still want to load data immediately, but after the initial load we need to start some sort of polling mechanism like that bash loop from earlier.
That bash loop was pretty great from a readability perspective, but it was also entirely synchronous. This doesn't fly in a web app since we still need to keep the thread open for various other activity.
Fortunately for us, we live in the same time period as Ember Concurrency. It's a great way to make asynchronous loops look like they are synchronous. It also has task cancelation built right in.

Here's a first stab at a polling loop using Ember Concurrency. In the setupController hook, after
the model hook has safely completed, we perform this watch task, providing the model as an
argument.
The watch task uses a common Ember Concurrency pattern, utilizing an infinite while loop in
which we request data and wait a couple second before making another blocking request.
// routes/jobs/job/index.js
import Route from '@ember/routing/route';
import { task, timeout } from 'ember-concurrency';
export default Route.extend({
setupController(controller, model) {
this.get('watch').perform(model);
return this._super(...arguments);
},
watch: task(function*(model) {
while (!Ember.testing) {
try {
yield this.get('store').findRecord('job', model.get('id'), {
reload: true,
adapterOptions: { watch: true },
});
yield timeout(2000);
} catch (e) {
yield e;
}
}
}),
});
You can see in this watch task the Ember Data request from earlier.
// routes/jobs/job/index.js
import Route from '@ember/routing/route';
import { task, timeout } from 'ember-concurrency';
export default Route.extend({
setupController(controller, model) {
this.get('watch').perform(model);
return this._super(...arguments);
},
watch: task(function*(model) {
while (!Ember.testing) {
try {
yield this.get('store').findRecord('job', model.get('id'), { reload: true, adapterOptions: { watch: true }, }); yield timeout(2000);
} catch (e) {
yield e;
}
}
}),
});You may also have noticed that we aren't doing anything with the result of findRecord. That's
because we don't have to. The records that findRecord returns are references to persistent objects
in the store.
This means even though the poll loop in this EC task does nothing with the return value, the model on the controller is still updated, since it points to the same persistent object that reloaded.
Okay! So that's it, right? The adapter changes make it so we can make blocking requests, the service allows us to keep track of the current index value for any URl, and the route changes mean we're indefinitely polling for changes.
Done.

Unfortunately, not quite. This works well for watching a single resource, but we also have to watch lists and relationships. And a consequence of lists and relationships means removing things from the store.

Let's start with watching lists. This one is straight forward. We have to override findAll in the
adapter, and we get to recycle WatchList, since it works on any URL.
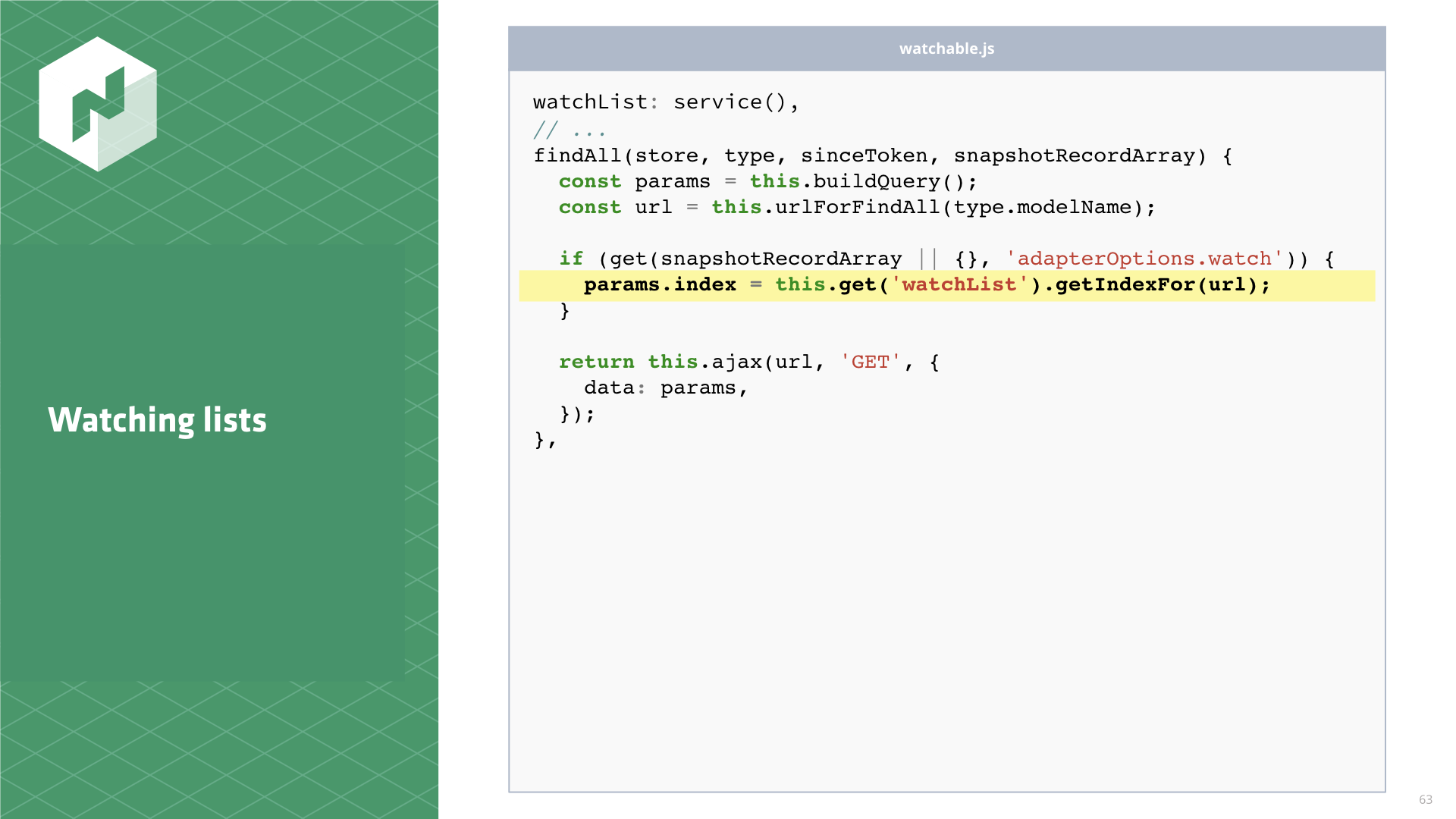
This should look familiar. Same pattern as findRecord now applied to findAll.
// adapters/watchable.js
watchList: service(),
// ...
findAll(store, type, sinceToken, snapshotRecordArray) {
const params = this.buildQuery();
const url = this.urlForFindAll(type.modelName);
if (get(snapshotRecordArray || {}, 'adapterOptions.watch')) {
params.index = this.get('watchList').getIndexFor(url); }
return this.ajax(url, 'GET', {
data: params,
});
},
Next up, watching relationships. This one is trickier.
There is no existing store method for fetching a relationship. Under Ember Data, these requests are made by reading relationship properties on models.
So I had to invent something. A new reloadRelationship method.
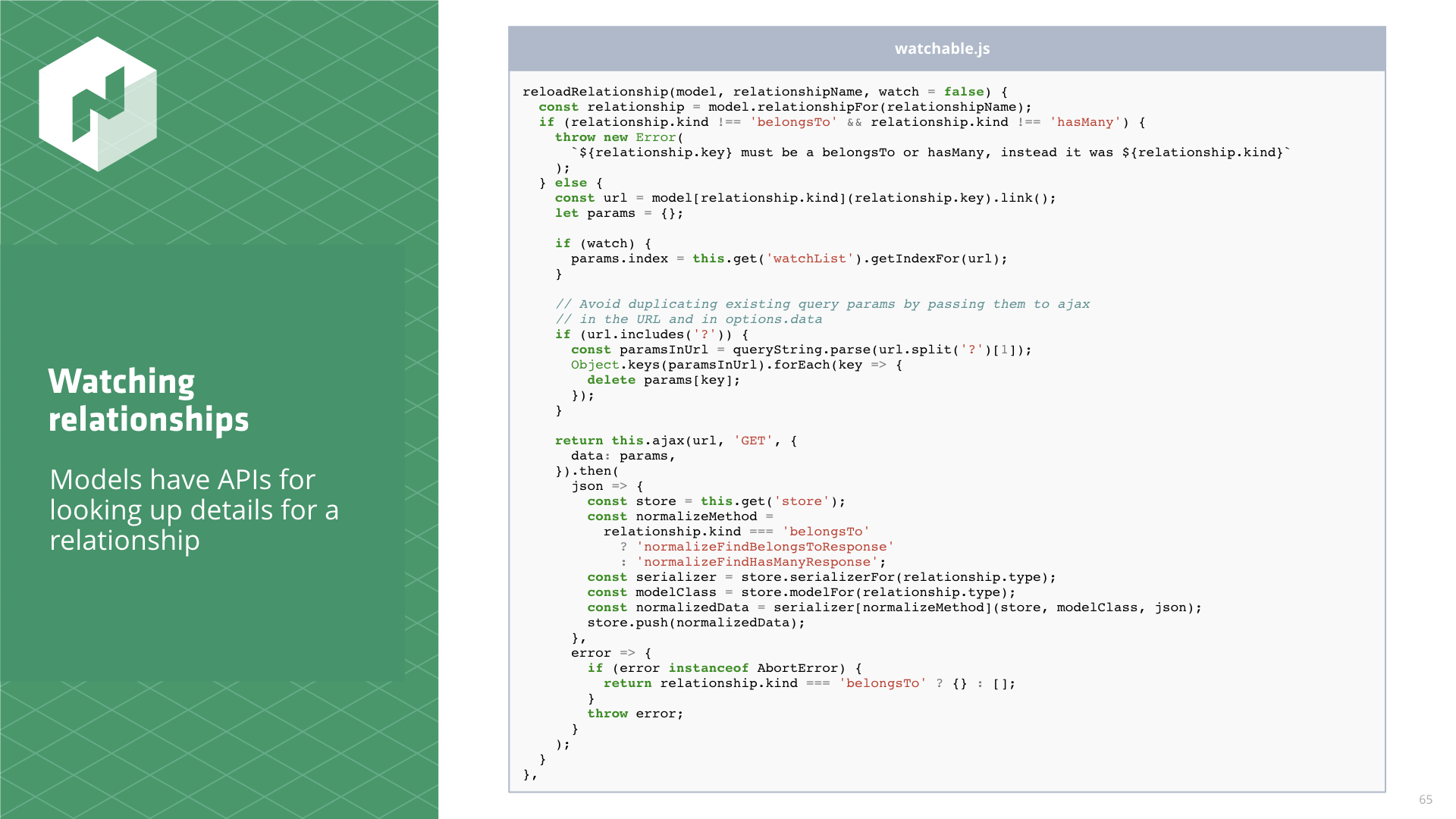
So here's a big pile of code. It's not as clean as the changes to findRecord and findAll, but
of course it isn't. This is an entirely new method. I'm just pleased that I was able to write it at
all.
Models have a relationship API that can be used to discover the appropriate HTTP request to make given just a model and a relationship name.
reloadRelationship(model, relationshipName, watch = false) {
const relationship = model.relationshipFor(relationshipName);
if (relationship.kind !== 'belongsTo' && relationship.kind !== 'hasMany') {
throw new Error(
`${relationship.key} must be a belongsTo or hasMany, instead it was ${relationship.kind}`
);
} else {
const url = model[relationship.kind](relationship.key).link();
let params = {};
if (watch) {
params.index = this.get('watchList').getIndexFor(url);
}
// Avoid duplicating existing query params by passing them to ajax
// in the URL and in options.data
if (url.includes('?')) {
const paramsInUrl = queryString.parse(url.split('?')[1]);
Object.keys(paramsInUrl).forEach(key => {
delete params[key];
});
}
return this.ajax(url, 'GET', {
data: params,
}).then(
json => {
const store = this.get('store');
const normalizeMethod =
relationship.kind === 'belongsTo'
? 'normalizeFindBelongsToResponse'
: 'normalizeFindHasManyResponse';
const serializer = store.serializerFor(relationship.type);
const modelClass = store.modelFor(relationship.type);
const normalizedData = serializer[normalizeMethod](store, modelClass, json);
store.push(normalizedData);
},
error => {
if (error instanceof AbortError) {
return relationship.kind === 'belongsTo' ? {} : [];
}
throw error;
}
);
}
},
Now to remove records. There's the findAll case and the watchRelationship case. The findAll
case is pretty simple: if a record in the store isn't also in the new response, then that record
needs to be removed from the store.
For the watchRelationship case, we need to remove records from the store of the relationship type
that's being watched that aren't also in this response.
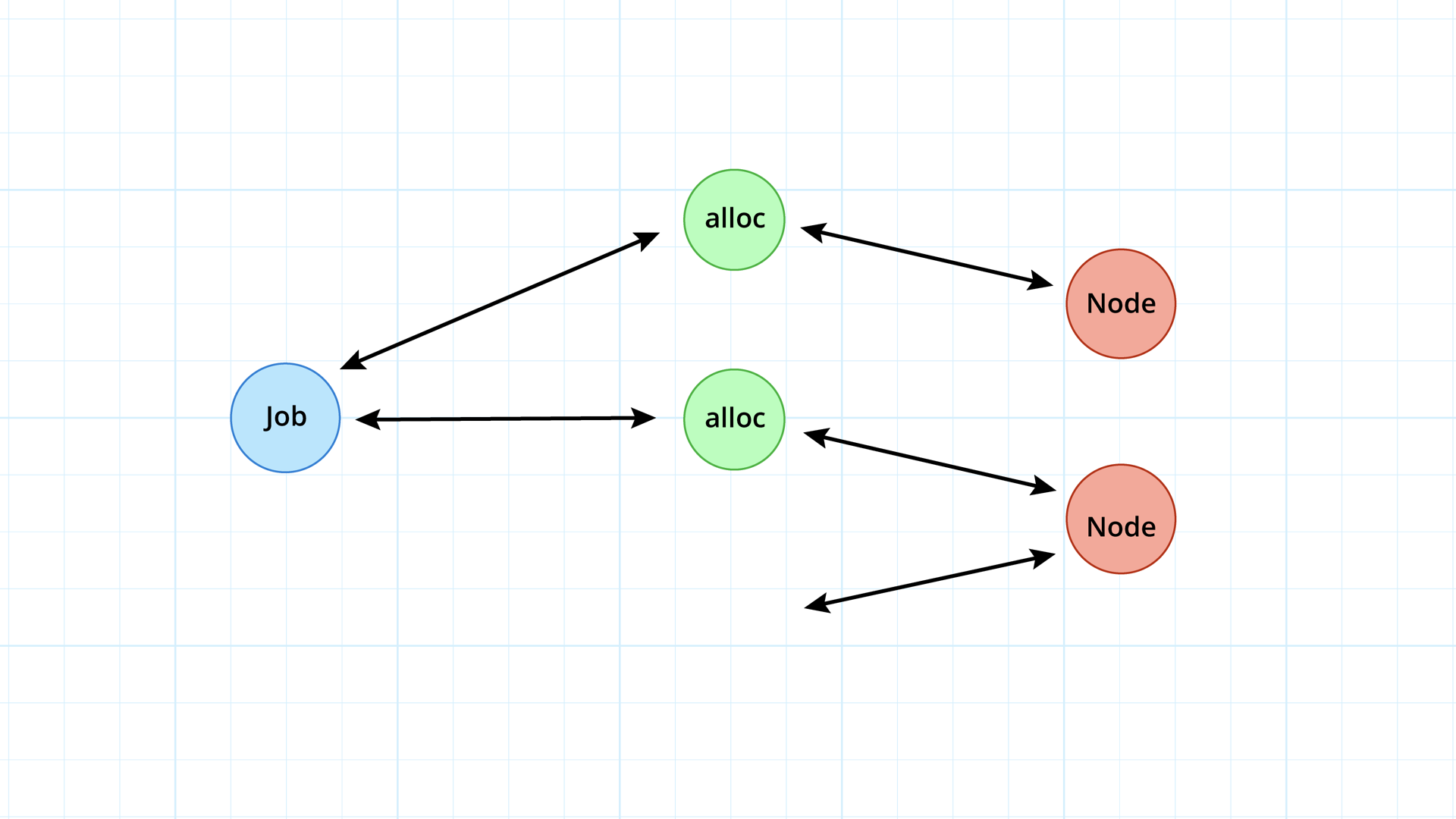
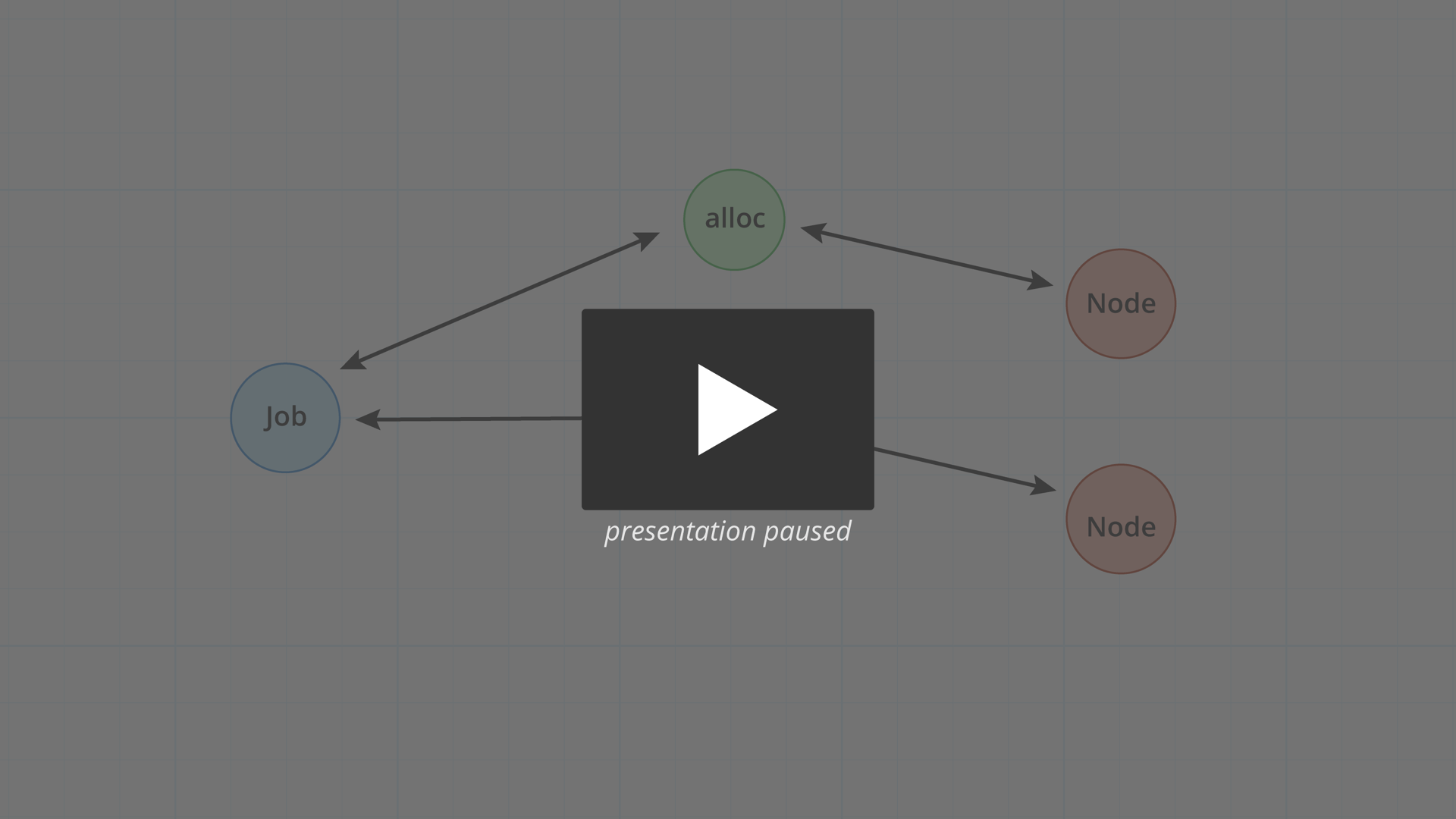
It's a tricky mouthful of words, so I think a diagram might help explain this.

Here's a job with a hasMany relationship to allocs. The job has three allocations. The allocations are also associated to nodes. Each alloc has a belongsTo relationship with a node. Nodes have a hasMany relationship with allocs.

By default, findHasMany adds and removes relationship links related to this model, but it doesn't
remove anything from the store.
// adapters/application.js
findHasMany(store, snapshot, link, relationship) {
return this._super(...arguments);
}So if we don't touch this default behavior, the impact on the object graph looks like this.

The link between the job and allocation is gone, but the allocation remains. We know from the latest
watchRelationship response that the allocation is gone, so we need to remove it somehow.

We can remove related records by using the relationship API to traverse records and find the records on the other side of the relationship (allocations in this case) that are associated with the model whose relationship we are watching (job in this case).
// adapters/application.js
findHasMany(store, snapshot, link, relationship) {
return this._super(...arguments).then(payload => {
const relationshipType = relationship.type;
const inverse = snapshot.record.inverseFor(relationship.key);
if (inverse) {
store
.peekAll(relationshipType)
.filter(record => record.get(`${inverse.name.id}`) === snapshot.id) .forEach(record => {
record.unloadRecord(); });
}
return payload;
});
}First, we this inverse object, which contains the property name for the other side of the
relationship. Then, we filter all records of the relationship type (allocations) down to only the
records whose value for inverse.name.id (the property name for the other side of the relationship)
is equal to this snapshot's id.
For each of those matching records, we call unloadRecord to get it out of the store.
This still isn't quite enough. This leaves us with this object graph, which is clearly invalid. The allocation was deleted, and the link from the job to the allocation was removed, but the other relationships on that allocation are still present.
This leads to runtime issues, believe me, I tried.

Okay, simple enough, we just need to clear those relationships out before unloading the record.
There's a neat trick for doing this. store.push is typically associated with putting data into the
Ember Data store, but it can also be thought of as a low-level API for manipulating the data in the
store.
We can create a JSONAPI payload that updates the record we want to remove to null out any relationships.
For belongsTo relationships, this means setting the relationship value to null. For hasMany
relationships, this means setting the relationship value to [].
We can replace our earlier call to record.unloadRecord with a call to our new util:
removeRecord(store, record).
// utils/remove-record.js
export default function removeRecord(store, record) {
const relationshipMeta = [];
record.eachRelationship((key, { kind }) => {
relationshipMeta.push({ key, kind });
});
store.push({
data: {
id: record.get('id'),
type: record.constructor.modelName,
relationships: relationshipMeta.reduce((hash, rel) => {
hash[rel.key] = { data: rel.kind === 'hasMany' ? [] : null };
return hash;
}, {}),
},
});
record.unloadRecord();
}
// Sample JSONAPI payload provided to store.push
// {
// id: “alloc-1”,
// type: “allocation”,
// relationships: {
// job: null,
// node: null,
// evaluations: [],
// }
// }
And now, we have the updated object graph we desire.
But I have to hit the pause button here. There's a good chance you're currently thinking, "This is absurd. Why can't Ember Data do this automatically?"
That's fair question, one I pondered too, but it doesn't make sense for Ember Data to do this out of the box. Ember Data's behavior always errs on the side of caution, and this removal behavior I want isn't universally true.
Not all hasMany relationships should delete the record when the relationship is removed. Alex Jones may have been removed from Twitter, but he wasn't deleted from the universe.
You can make an argument that it should be easier to do what I'm doing here, but there is no case to be made for it to happen automatically.

Back to the talk. At this point everything works.
- There's a new service for tracking indices by URL
findRecordwas overridden to optionally append the index query param to requestsfindAllwas overridden in a similar way- There's a new
reloadRelationshipmethod on adapters for reloading a relationship separately from property lookup on a model. - Data gets removed from the store to keep the client-side state of the world in sync with the server-side state of the world.

Now that it works, the next thing to do is make it nice. We do this by finding the right abstractions.
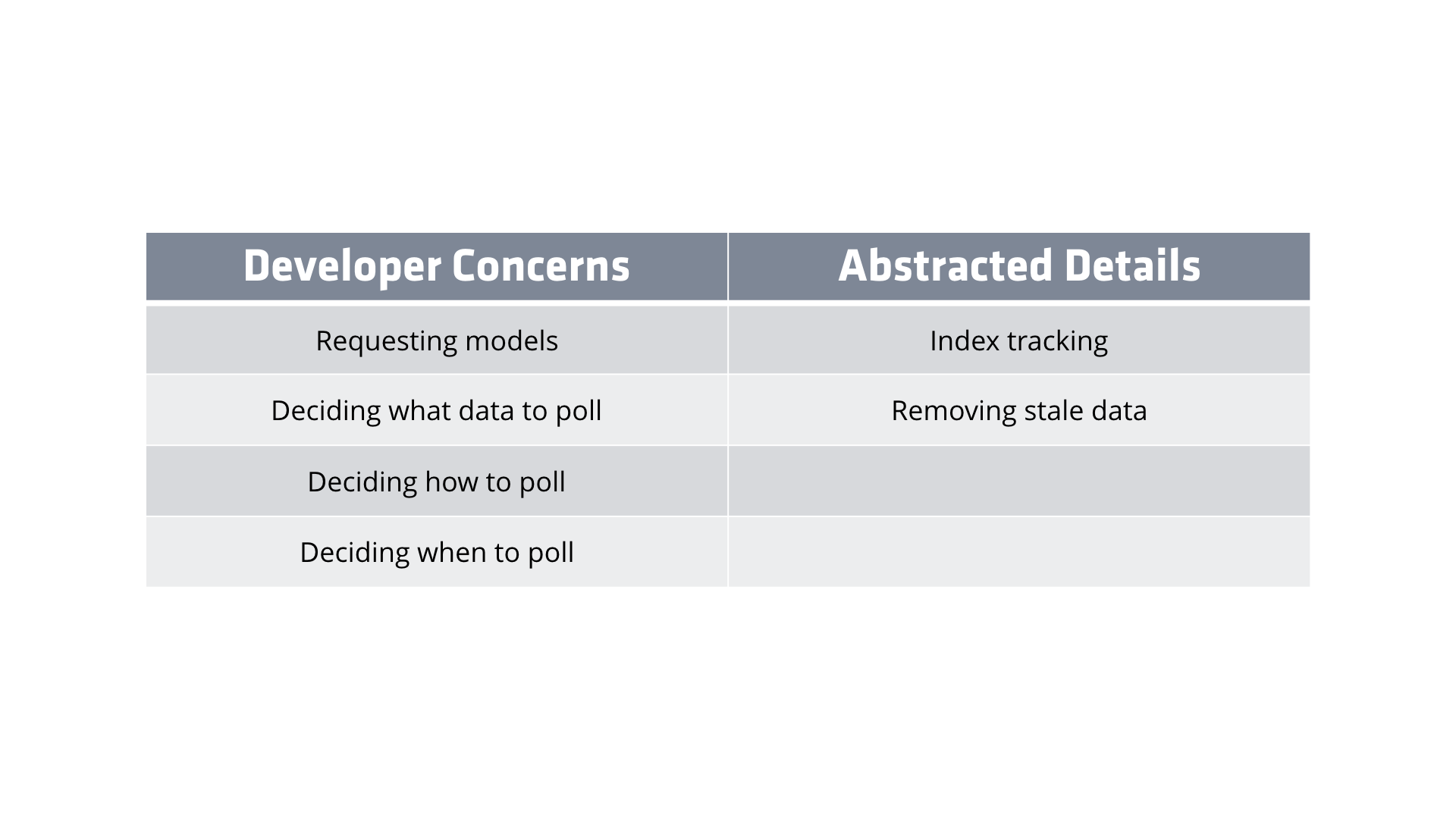
Let's review what our abstractions look like right now.
Under the developer's concerns are requesting models, deciding what data to poll, deciding how to poll, and deciding when to poll.
The abstracted details are index tracking (which happens in the adapter and WathList service abstractions), and remove stale data (which happens in the application adapter, along with that remove record util).

If you recall, the more stuff we have under the developer's concerns, the closer we get to Minerva in Her Study, and the more stuff we have under abstracted details, the closer we get to Smiley in Open Sans.
It's important to really emphasize that there is no wrong or right abstraction. It's a subjective prediction made with the goal of managing complexity without limiting developers by locking away situational parameters they need to adjust.
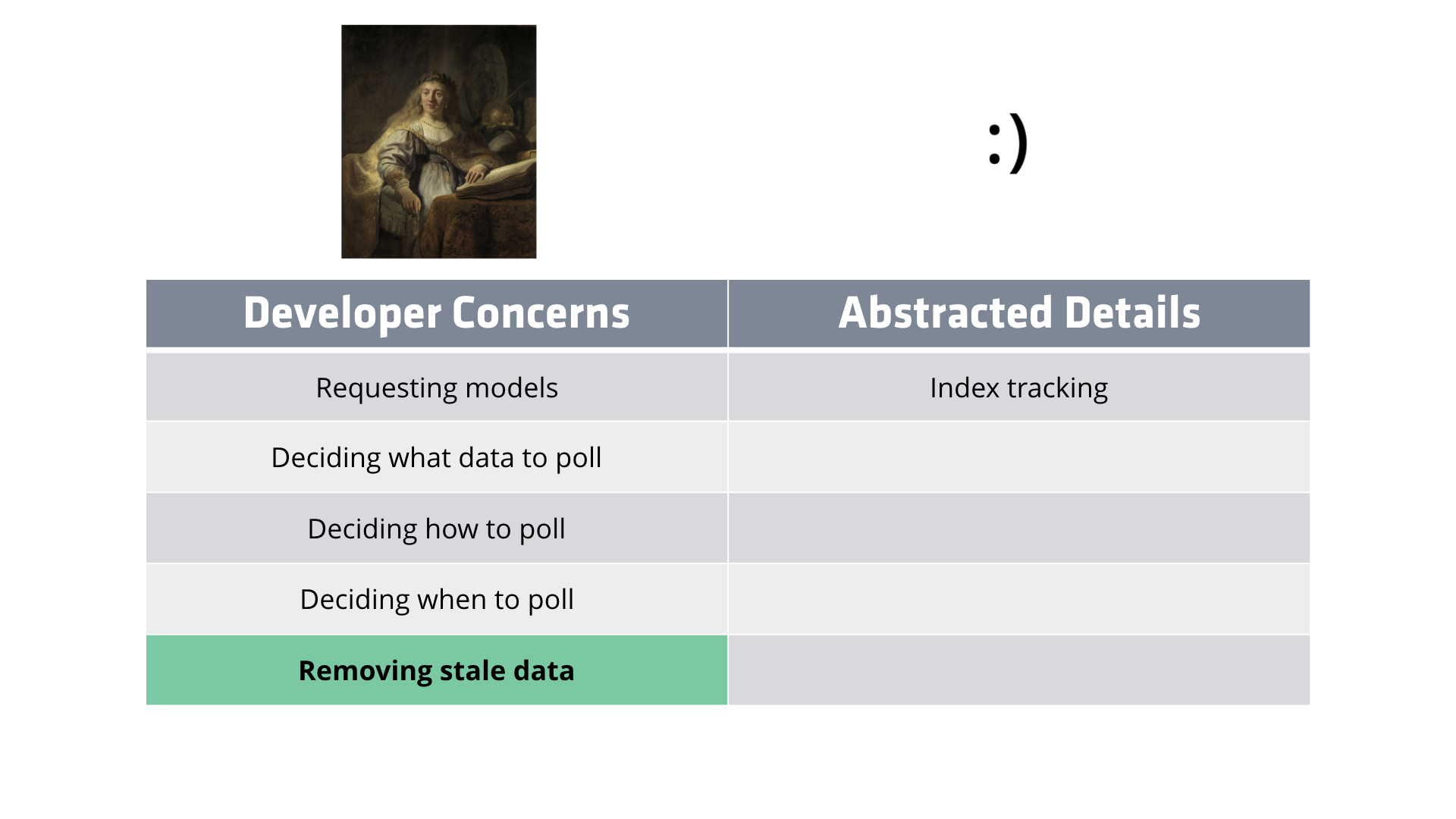
From here we could go less abstract by moving the removal of stale data under the developer's concerns. Afterall, we already determining that the way we are removing data isn't universally sound.

We could also go all in on abstractions by putting everything other than requesting models under abstracted details. This would look something like all data automatically polling without any changes to your route code. Which sounds nice, but it prohibits fetching data without watching it unless you work around the abstraction.

Knowing what I know about Ember, Ember Data, and most importantly, the Nomad UI, this is the level of abstraction I went with. How and when to poll can be safely abstracted, but which models to request and what data should be polled remains a developer concern.

Let's start with abstracting how to poll. How do we do this?
We're currently using Ember Concurrency tasks for polling, and these tasks are essentially a specialized computed property. Ember has this existing concept of computed property macros, we can leverage that concept here.
A computed property macro can be written many different ways, how do we choose which way to go with? The question I ask is always, "what are truly parameters and not the mechanics of polling?"

Here's what that task looks like:
// utils/properties/watch.js
import Ember from 'ember';
import { get } from '@ember/object';
import RSVP from 'rsvp';
import { task, timeout } from 'ember-concurrency';
export function watchRecord(modelName) {
return task(function*(id, throttle = 2000) { if (typeof id === 'object') { id = get(id, 'id'); } while (!Ember.testing) { try { yield this.get('store').findRecord(modelName, id, { reload: true, adapterOptions: { watch: true }, }); yield timeout(throttle); } catch (e) { yield e; } } }).drop();
}Notice how the bulk of this task macro is the original task extracted from the route and moved into this util.
The other detail of note is how the watchRecord task macro expects a modelName parameter. Then,
the task itself closes over this argument to create a task that now only expects an id and an
optional throttle parameter.
Onto abstracting when to poll. Currently we are starting polls in the setupController method of
routes. The typical way to abstract route behaviors is through inheritence. In Ember, we do this
with Mixins.

This is what that mixin looks like. It still uses setupController, since this will get mixed into
the route, but now it's out of sight out of mind. We also fixed a bug: we weren't canceling tasks
when we left pages before now.
// mixins/with-watchers.js
import Mixin from '@ember/object/mixin';
import { computed } from '@ember/object';
import { assert } from '@ember/debug';
export default Mixin.create({
watchers: computed(() => []),
cancelAllWatchers() {
this.get('watchers').forEach(watcher => {
assert(
'Watchers must be Ember Concurrency Tasks.',
!!watcher.cancelAll
);
watcher.cancelAll();
});
},
startWatchers() {
assert('startWatchers needs to be overridden in the Route', false);
},
setupController() {
this.startWatchers(...arguments);
return this._super(...arguments);
},
actions: {
willTransition() {
this.cancelAllWatchers();
},
},
});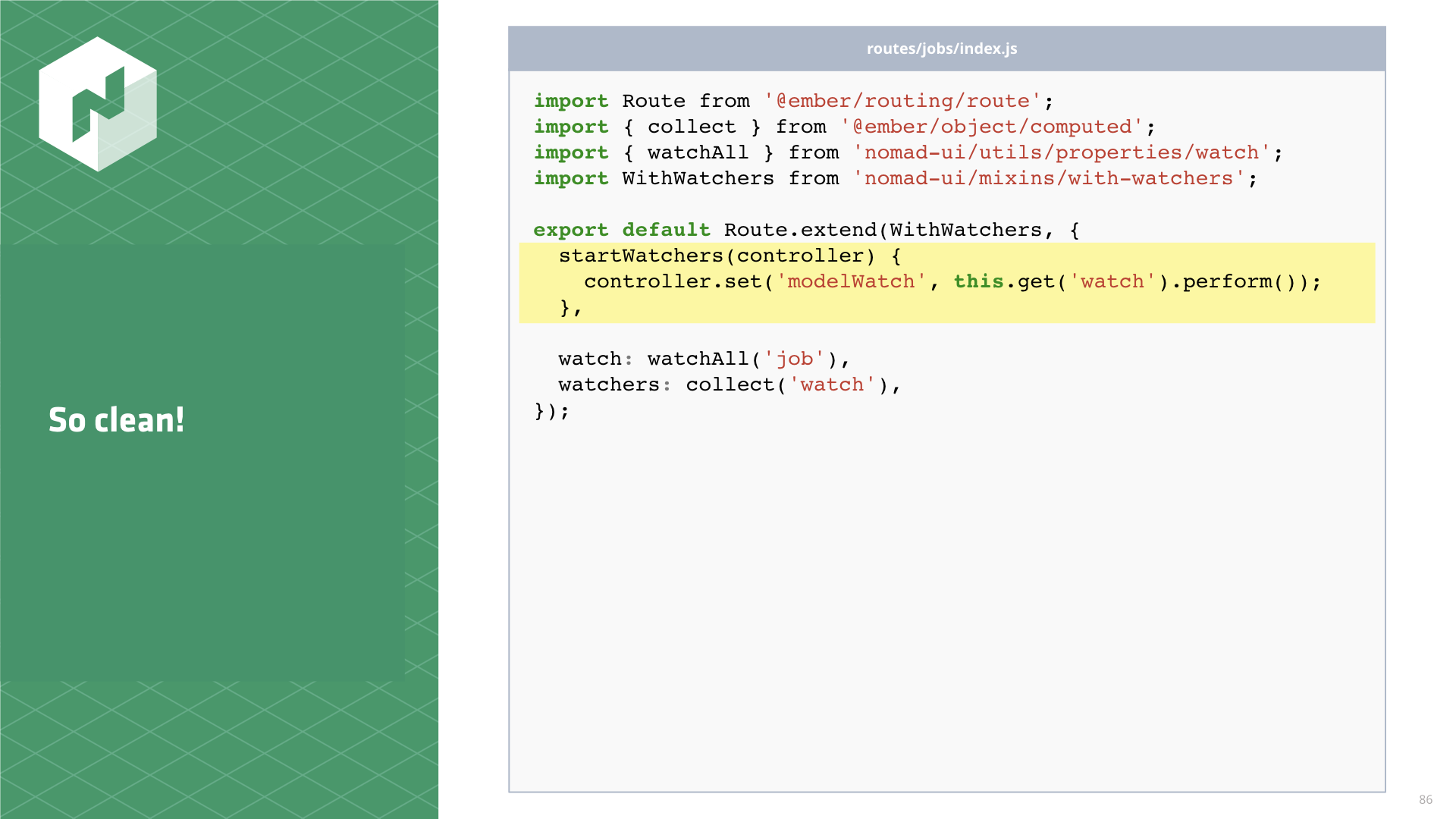
This is what a route looks like now. So much cleaner!
// routes/jobs/index.js
import Route from '@ember/routing/route';
import { collect } from '@ember/object/computed';
import { watchAll } from 'nomad-ui/utils/properties/watch';
import WithWatchers from 'nomad-ui/mixins/with-watchers';
export default Route.extend(WithWatchers, {
startWatchers(controller) { controller.set('modelWatch', this.get('watch').perform()); },
watch: watchAll('job'),
watchers: collect('watch'),
});Looking at this, you might be compelled to reduce it further. Maybe by moving this startWatchers
nonsense into the mixin. If you recall, some of the watcher task macros take arguments to calls to
perform. We can't abstract these details away.
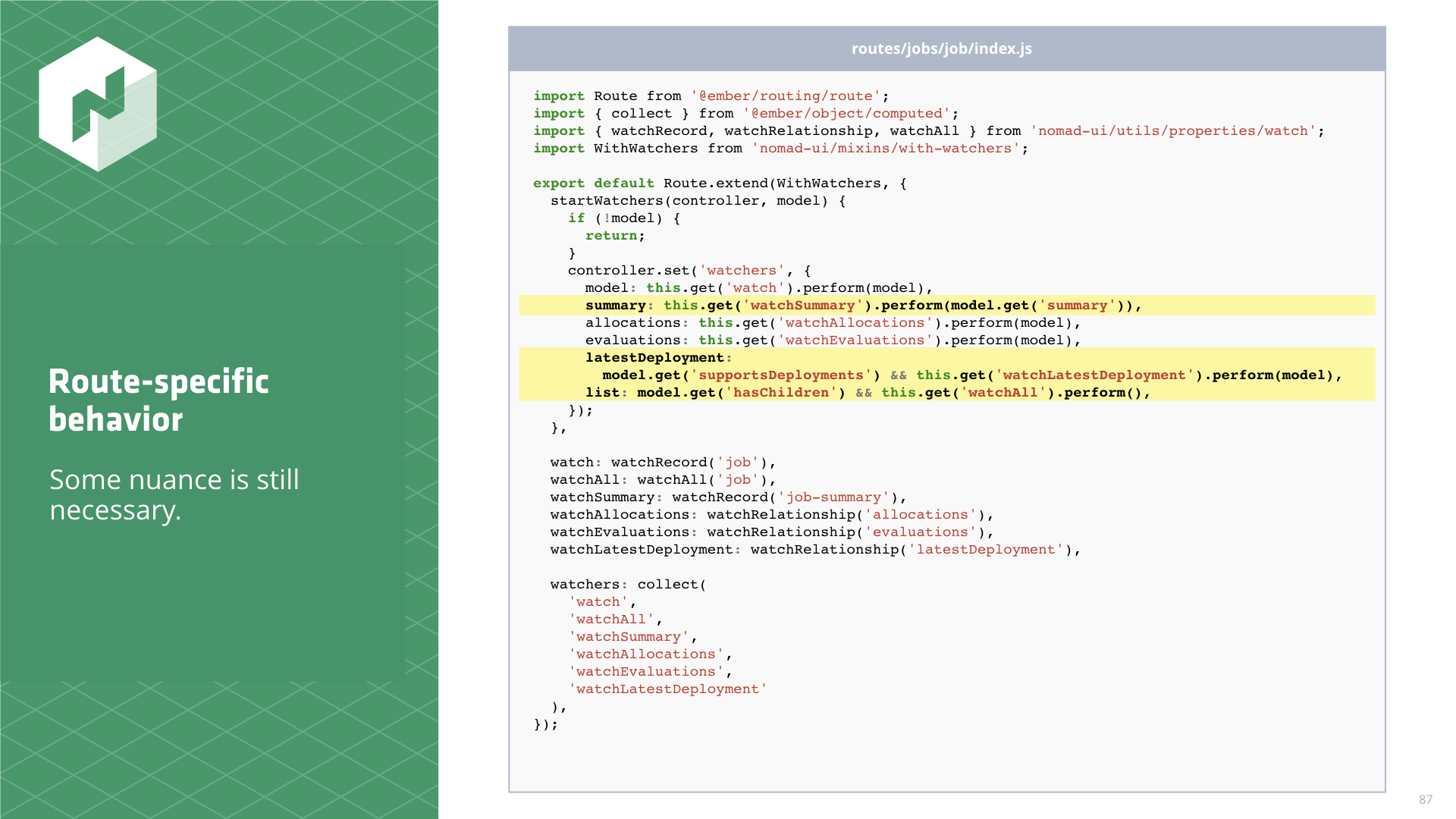
Here's an example of another, more involved, route. It has multiple watchers to start, some of them require arguments, and a couple are even optionally started based on the shape of the model.
// routes/jobs/job/index.js
import Route from '@ember/routing/route';
import { collect } from '@ember/object/computed';
import { watchRecord, watchRelationship, watchAll } from 'nomad-ui/utils/properties/watch';
import WithWatchers from 'nomad-ui/mixins/with-watchers';
export default Route.extend(WithWatchers, {
startWatchers(controller, model) {
if (!model) {
return;
}
controller.set('watchers', {
model: this.get('watch').perform(model),
summary: this.get('watchSummary').perform(model.get('summary')), allocations: this.get('watchAllocations').perform(model),
evaluations: this.get('watchEvaluations').perform(model),
latestDeployment: model.get('supportsDeployments') && this.get('watchLatestDeployment').perform(model), list: model.get('hasChildren') && this.get('watchAll').perform(), });
},
watch: watchRecord('job'),
watchAll: watchAll('job'),
watchSummary: watchRecord('job-summary'),
watchAllocations: watchRelationship('allocations'),
watchEvaluations: watchRelationship('evaluations'),
watchLatestDeployment: watchRelationship('latestDeployment'),
watchers: collect(
'watch',
'watchAll',
'watchSummary',
'watchAllocations',
'watchEvaluations',
'watchLatestDeployment'
),
});
So that's that. It's all the patterns I needed to make all of the views in the Nomad UI realtime. I implement this on every page, and I'm feeling really good about this. Before getting ready to merge this work, I want to make sure it works, so I start clicking around.
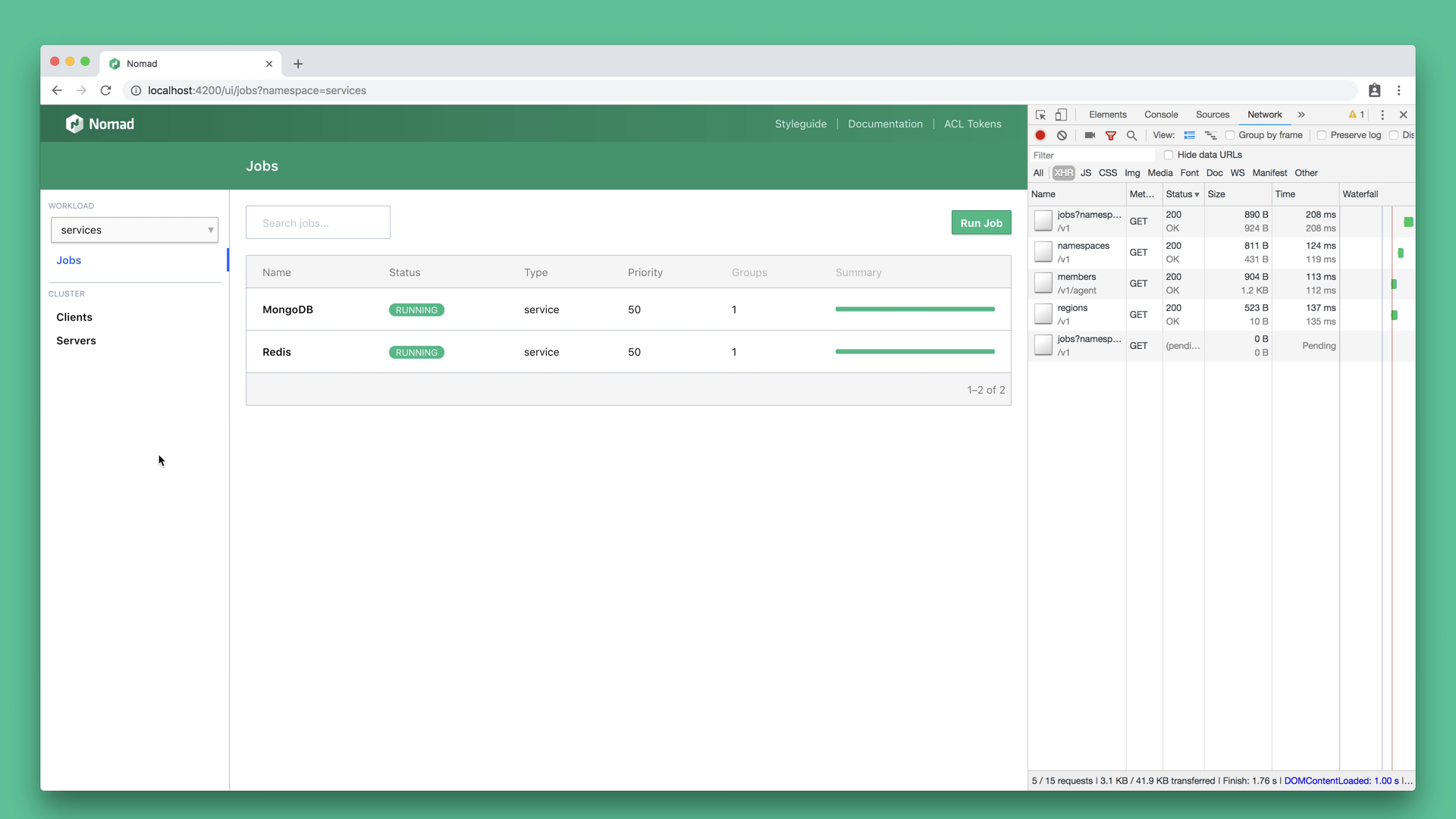
This slide is a video. Watch the recording to see the UI change states and reveal the bug.
Okay, here's a cluster. Everything looks good. Hmm, MongoDB, that can't be good. Let's see what it is up to. Everything is fine, but I'm skeptical. Okay, versions seem fine, deployments seem fine. Is the client doing okay?
Wait, why isn't the client page loading? What's going on the network tab? What's up with all these pending requests? Shouldn't the model hook still return immediately instead of blocking?

Sigh...
Step 5: Fight the bugs.

So requets are stuck in a pending state. Why is that?
Turns out this has nothing to do with Ember. It also has nothing to do with the code we just wrote. That code is flawless, believe it or not. This has everything to do with browsers having a max number of concurrent HTTP connections per domain.

No matter what framework you choose, eventually browsers will be your problem.
Earlier on in my career, I would have thrown my hands in the air and bemoaned technology. I would have cried about how this is why we can't have nice things.
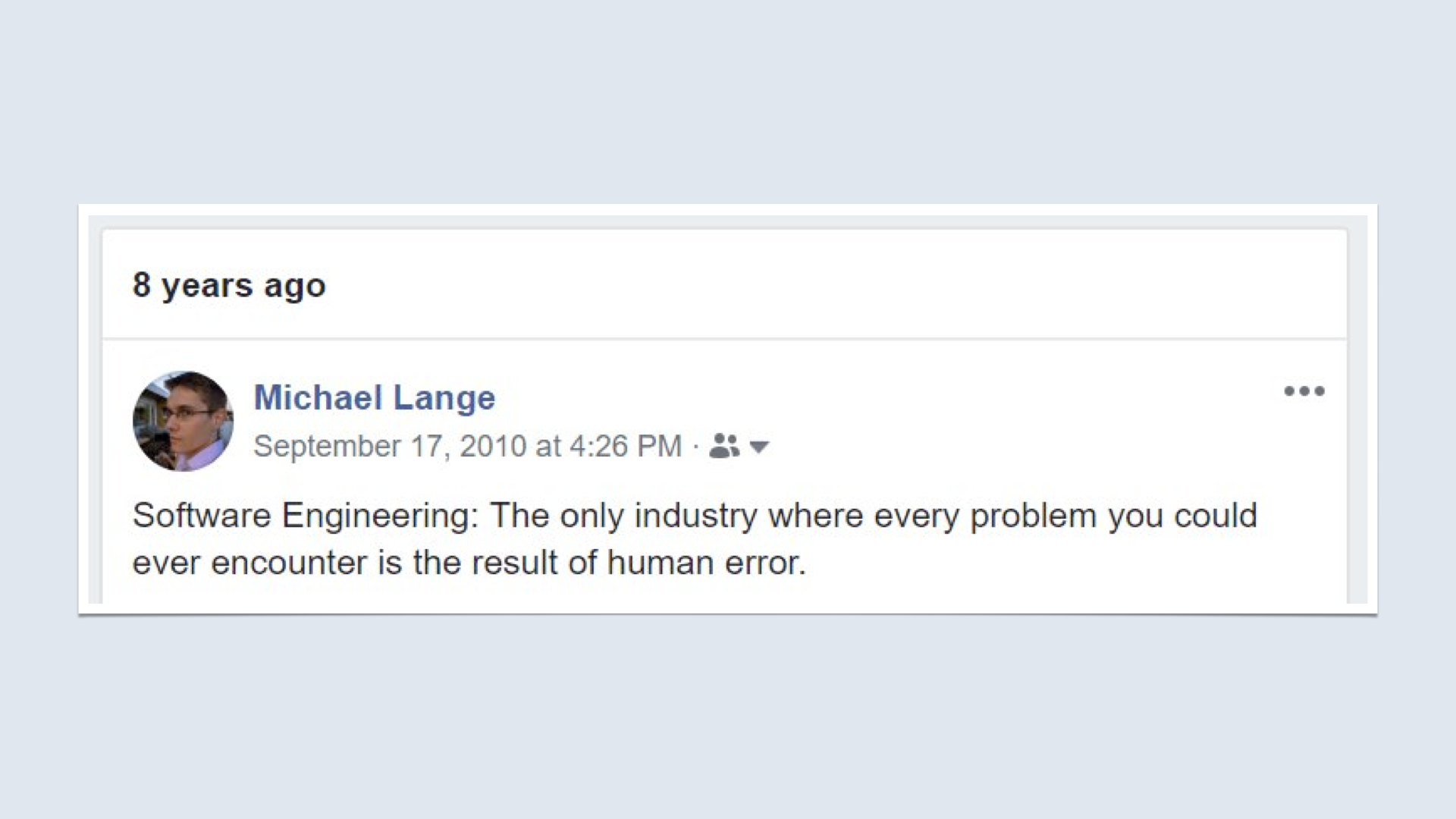
In fact, eight years ago, I did nearly exactly this. I said, "Software Engineering; the only industry where every problem you could ever encounter is the result of human error."
There is still some truth to this, by nowadays my outlook is a little more positive.

Now I would say something like, "Most people are making the best decisions they can in the situations they are in."

Turns out this is also true. I dug up the original HTTP/1.1 RFC, numbered 2616 to read the original reasoning.
A single-user client SHOULD NOT maintain more than 2 connections with any server or proxy. &ellip; These guidelines are intended to improve HTTP response times and avoid congestion.
— https://tools.ietf.org/html/rfc2616#page-46
Browsers today are actually breaking the rules and being generous by allowing six or more concurrent connections per server or proxy. Brwoser vendors recognize that the Internet is different now, and networking gear (especially on the server side) is much better.
Nonetheless, we're in this situation, so what do we do about it?

One option is using HTTP/2, which is in fact better than HTTP/1.1 in every single way. It will cure all your problems and it is literally magic. For our purposes, HTTP/2 is an option because it allows for unlimited numbers of concurrent connection per host by means of actually having a single multiplexed long-lived connection per host. Sounds perfect.

Unfortuantely, we can't use HTTP/2. Despite the HTTP/2 spec not mandating a secure connection, browsers, will still only use HTTP/2 over TLS.
As it turns out, Nomad supports TLS because security is important, but it is still optional. We can't say TLS is optional but required to use the web UI. That's unacceptable.

Another possible solution is domain sharding.
This is when you use multiple sub-domains to bypass the max concurrent connections per domain limit.
It doesn't matter if all you're doing is creating a reverse proxy to the same exact server, which is amusing, but at least browser try to prevent you from shooting yourself in the foot.

But Nomad isn't SaaS! Customers install Nomad on their own machines and we take operational simplicity very seriously.

If our getting started guide read "Using the Web UI. The first step is DNS" we would have to reconsider some things.

So that's out. What about option 3: request cancellation?
There's a good chance this is a corner of HTTP you haven't had to deal with, but HTTP requests can
be cancelled. XMLHttpRequest objects have an abort method for triggering cancellation. Ember Data
uses XHRs out of the box, so that's a good sign. But Ember Data
does not provide abort hooks.

Well I have no other options, so let's do request cancellation with Ember Data anyway. Conceptually, this can be done in four steps.
- Capture XHRs in some sort of cache to abort later
- Remove XHRs from the cache when they resolve
- Write cancel methods that mirror the watchable method signatures
- Call the cancel methods in our polling code
Let's see where we can stick the code to do these things.

First: capture all the XHRs. We can do this by making a registry of requests in a similar manner to the WatchList service.
// adapters/watchable.js
xhrs: computed(function() {
return {
list: {},
track(key, xhr) {
if (this.list[key]) {
this.list[key].push(xhr);
} else {
this.list[key] = [xhr];
}
},
cancel(key) {
while (this.list[key] && this.list[key].length) {
this.remove(key, this.list[key][0]);
}
},
remove(key, xhr) {
if (this.list[key]) {
xhr.abort();
this.list[key].removeObject(xhr);
}
},
};
}),This is pretty straightfoward. XHRs are tracked by key (which ends up being a combination of the
URL and HTTP method). Requests can be canceled, and when this happens, they are removed. When XHRs
are removed, xhr.abort() is called, since that's the whole point of doing this, and then removed
from the registry.

Once we have this registry in place, we need to find a place to actually capture the XHR. We can do
this in the Adapter#ajaxOptions method. The ajaxOptions object grants an opportunity to hook
into the XHR lifecycle.
// adapters/watchable.js
ajaxOptions() {
const ajaxOptions = this._super(...arguments);
const key = this.xhrKey(...arguments);
const previousBeforeSend = ajaxOptions.beforeSend;
ajaxOptions.beforeSend = function(jqXHR) {
if (previousBeforeSend) {
previousBeforeSend(...arguments);
}
this.get('xhrs').track(key, jqXHR);
jqXHR.always(() => { this.get('xhrs').remove(key, jqXHR); }); };
return ajaxOptions;
},Before we send the HTTP request, we track it, and if the request closes from natural causes, we
still want to remove it from the registry. abort is idempotent, so we can reuse that remove
method.
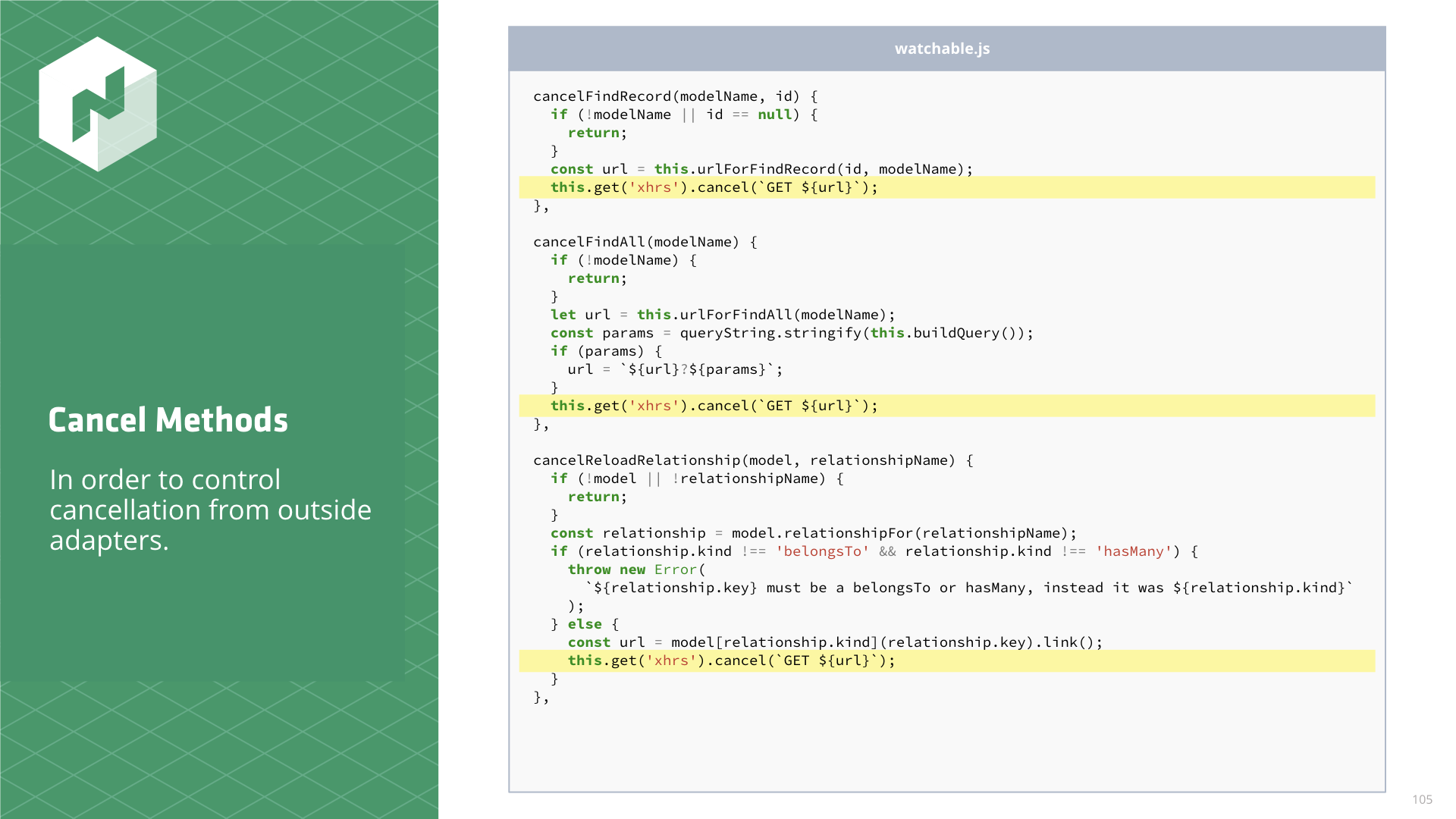
Also in the adapter are these cancel methods that match the method signature of the find methods.
This allows us to control when we cancel requests from outside the adapter using parameters we know must already be known outside of the adapter.
// adapters/watchable.js
cancelFindRecord(modelName, id) {
if (!modelName || id == null) {
return;
}
const url = this.urlForFindRecord(id, modelName);
this.get('xhrs').cancel(`GET ${url}`);},
cancelFindAll(modelName) {
if (!modelName) {
return;
}
let url = this.urlForFindAll(modelName);
const params = queryString.stringify(this.buildQuery());
if (params) {
url = `${url}?${params}`;
}
this.get('xhrs').cancel(`GET ${url}`);},
cancelReloadRelationship(model, relationshipName) {
if (!model || !relationshipName) {
return;
}
const relationship = model.relationshipFor(relationshipName);
if (relationship.kind !== 'belongsTo' && relationship.kind !== 'hasMany') {
throw new Error(
`${relationship.key} must be a belongsTo or hasMany, instead it was ${relationship.kind}`
);
} else {
const url = model[relationship.kind](relationship.key).link();
this.get('xhrs').cancel(`GET ${url}`); }
},
Now to call these cancel methods at the appropriate times. This would be the polling code, since it is the code that makes the requests in the first place.
Ember Concurrency has cancelable tasks, which helps us a lot here. By adding a finally clause to
the various watch task macros, we can add instructions that execute whenever a task is canceled.
Tasks are canceled whenever the loop is no longer relevant, (e.g., on page transitions), so this is perfect.
// utils/properties/watch.js
export function watchRecord(modelName) {
return task(function*(id, throttle = 2000) {
if (typeof id === 'object') {
id = get(id, 'id');
}
while (!Ember.testing) {
try {
yield this.get('store').findRecord(modelName, id, {
reload: true,
adapterOptions: { watch: true },
});
yield timeout(throttle);
} catch (e) {
yield e;
} finally {
this.get('store') .adapterFor(modelName) .cancelFindRecord(modelName, id); }
}
}).drop();
}
This works great for canceling requests, but there an unforeseen consequence. When an XHR is aborted,
an AbortError is thrown. This causes a promise to go into the catch handler which cascades into
a whole unwanted mess. We don't want an error thrown, and we don't want to be redirected to an error
page. The abort is expected, so we have to handle this somewhow.
The place to do this is the find methods.
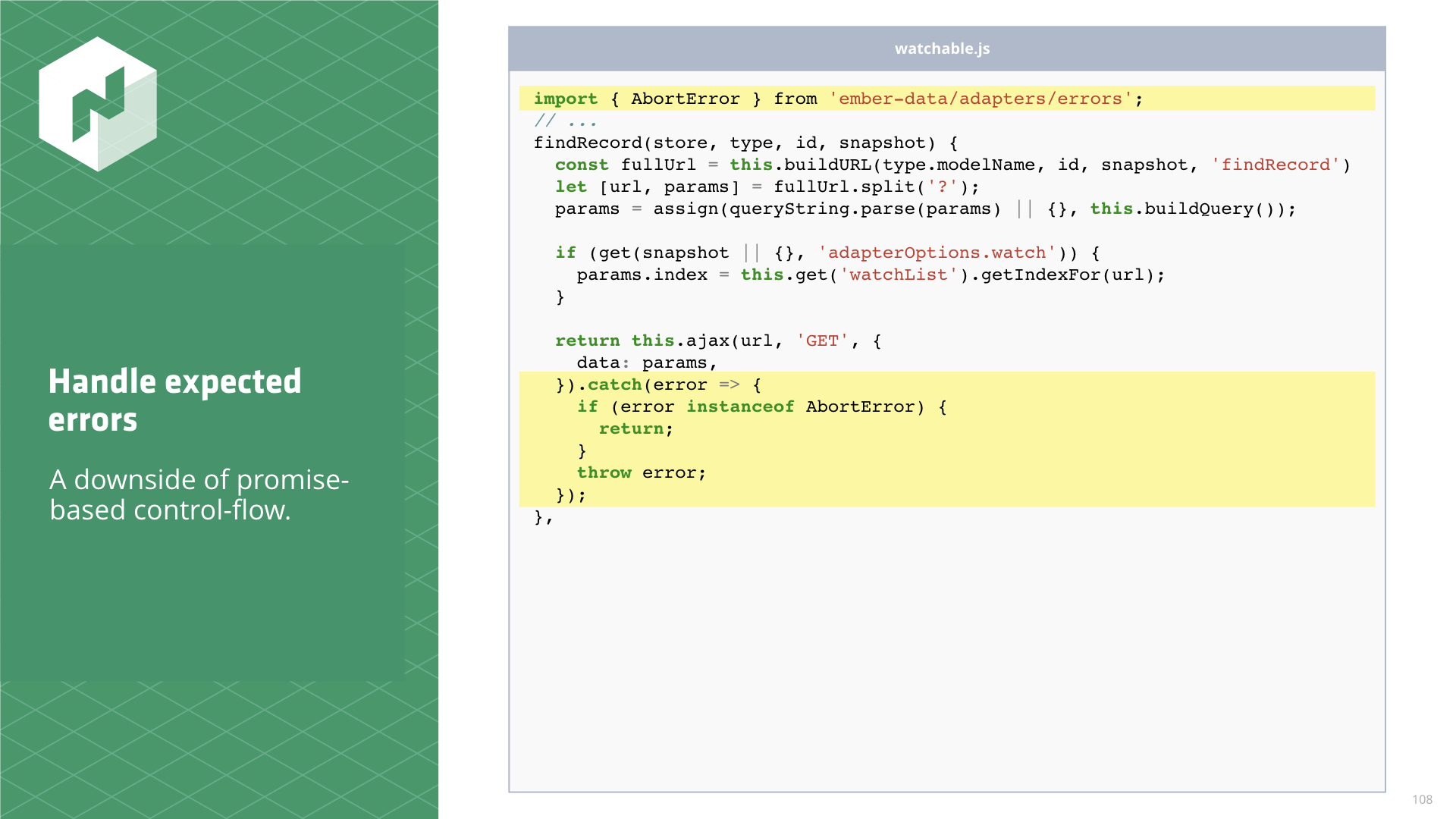
This isn't so bad to fix, but it's a bit of a bummer that we need to do it. It's just a consequence of promise-based control-flow.
We have to write our own catch handler to filter out AbortErrors. If the error isn't an
AbortError, rethrowing puts the error handling back on track.
// adapters/watchable.js
import { AbortError } from 'ember-data/adapters/errors';// ...
findRecord(store, type, id, snapshot) {
const fullUrl = this.buildURL(type.modelName, id, snapshot, 'findRecord');
let [url, params] = fullUrl.split('?');
params = assign(queryString.parse(params) || {}, this.buildQuery());
if (get(snapshot || {}, 'adapterOptions.watch')) {
params.index = this.get('watchList').getIndexFor(url);
}
return this.ajax(url, 'GET', {
data: params,
}).catch(error => { if (error instanceof AbortError) { return; } throw error; });},
Okay! That's it! Let's celebrate!
Some people celebrate by going out drinking or dancing. I like to sit alone and practice quiet reflection. I'm very fun at parties.
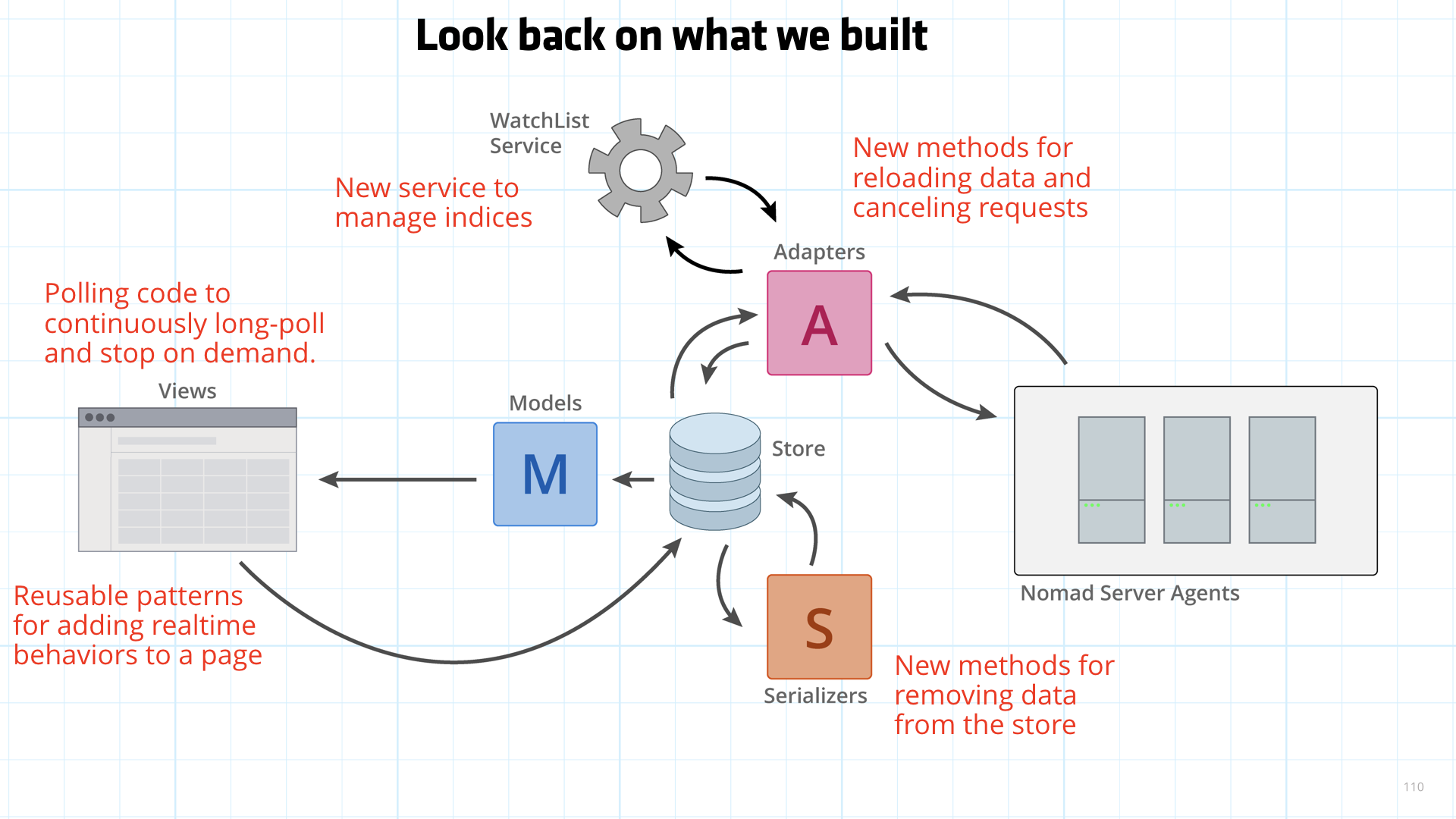
Let's look back on what we built.
- We made a new service to manage indices
- Added new methods for reloading data and canceling requests
- Wrote new methods for removing data from the store
- Came up with polling code to continuously long-poll and stop on demand
- Introduced reusable patterns for adding realtime behaviors to a page
This is a lot of stuff! On one hand it makes sense that we wrote a lot of code, it's a big feature, but we're using a framework. Shouldn't it be helping us?
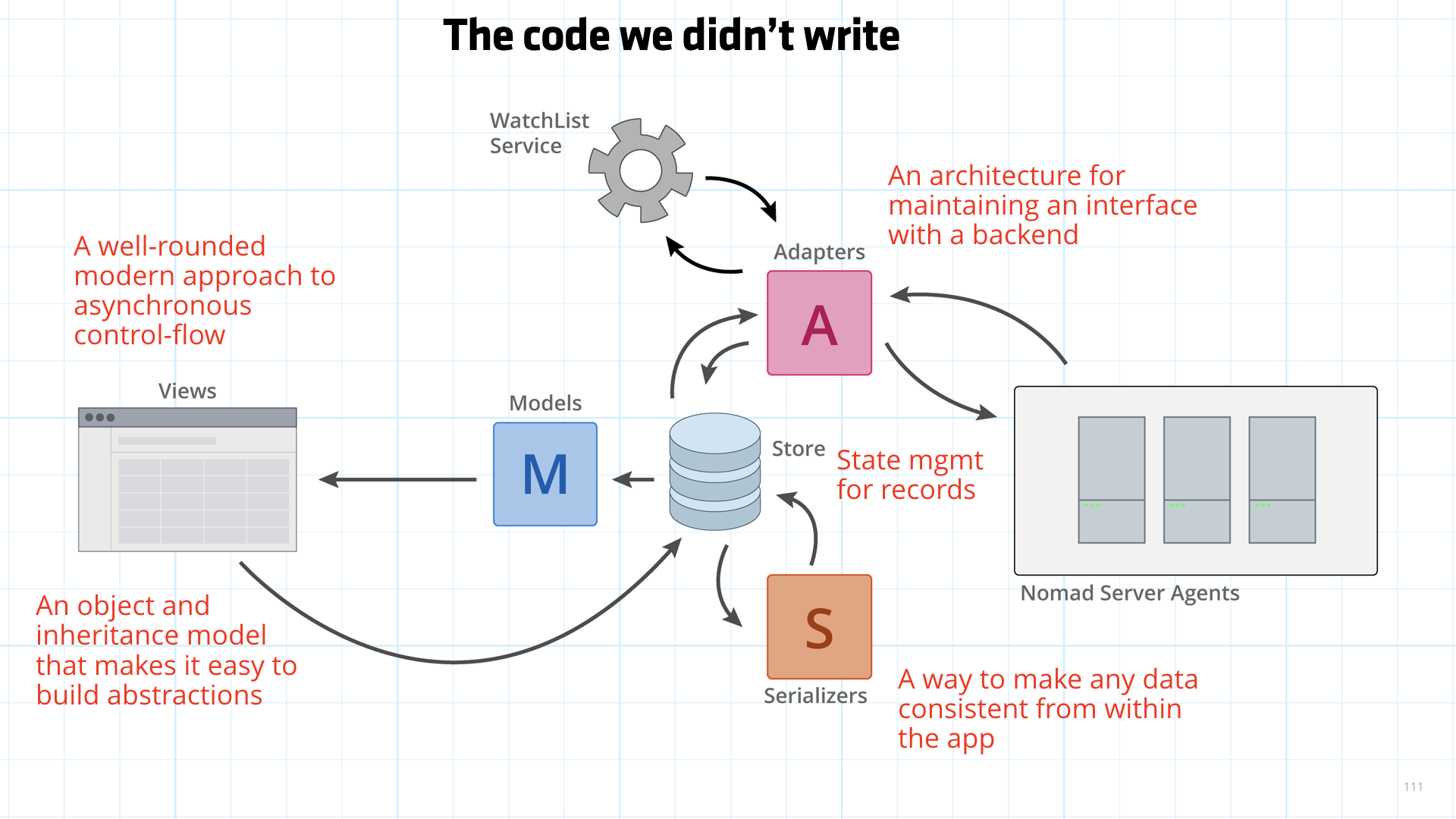
It should and it does! Consider all the code we didn't have to write.
- An architecture for maintaining an interface with a backend
- State management for records
- A away to make any data consistent from within the app
- A well-rounded modern approach to asynchronous control-flow
- An object and inheritance model that makes it easy to build abstractions
Not to mention that this little box I labeled "Views" is actually the entirely of Ember core.
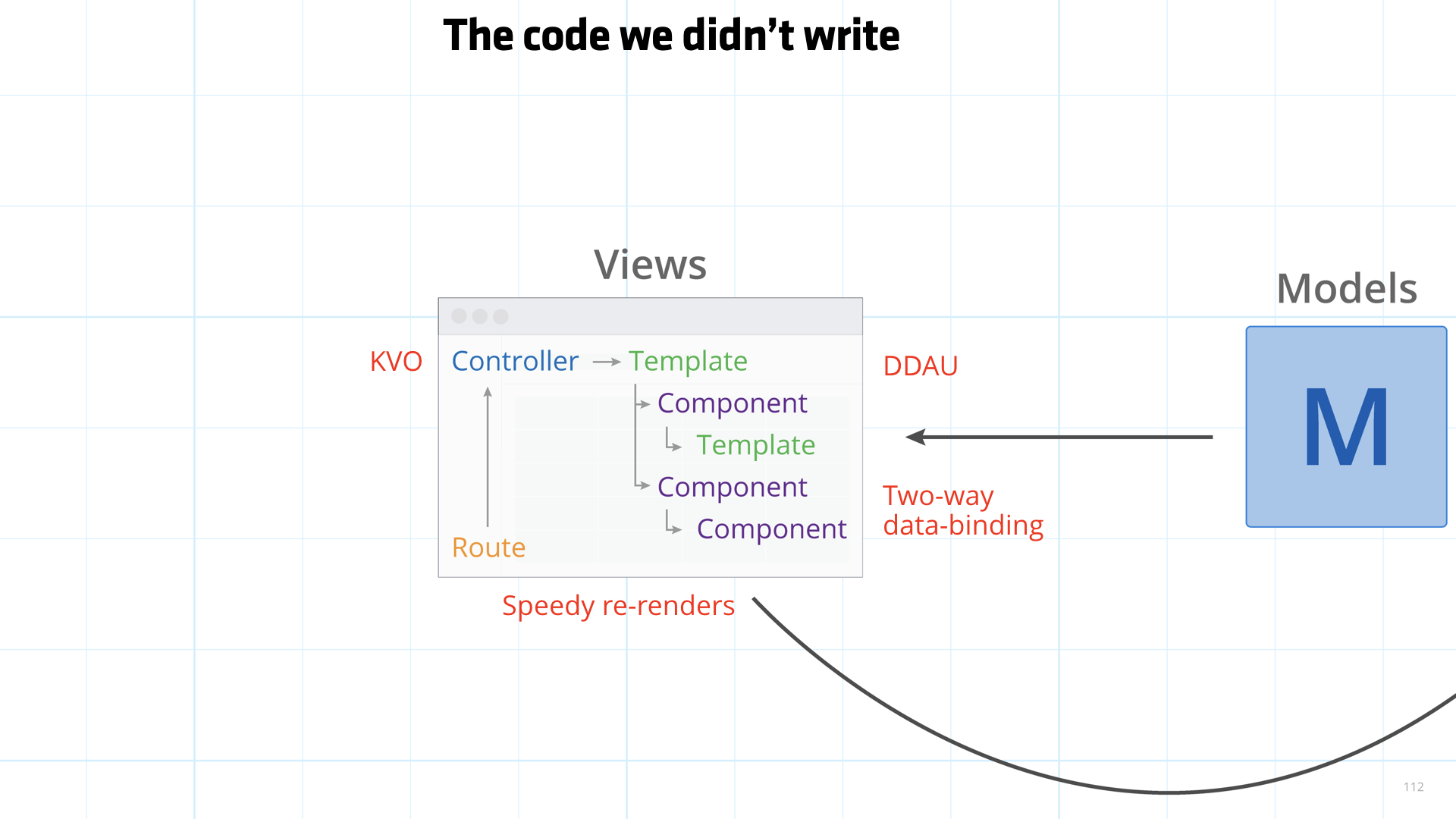
This includes
- Data-down, Actions-up
- Two-way data-binding
- Speedy re-renders
- Key-value observation
And more.

If we were to look at the distribution of code that gets run, the overwhelming majority of it was written by someone other than me. The Nomad UI is built on the shoulders of addons, Ember Data, and Ember.js.
(this is a totally unscientific pie chart, just trying to drive a point home)

So what's the takeaway?
- Products are all trying to be unique and differentiated
- By definition, frameworks only solve common problems
- We can use addons and build on top of Ember to create great new things
- We can think like framework authors to build software that might withstand the test of time and keep our coworkers happy

And there's one more thing...
This is all open source! Nomad and the Nomad UI are open source projects. You can read through the pull request that made the UI realtime.

Not only is Nomad open source and using Ember, but all our products are.
- Consul, and the Consul UI
- Vault, and the Vault UI
- Nomad, and the Nomad UI
- Terraform Enterprise (not open source, but it still uses Ember!)

Thank you!
Michael Lange, @DingoEatingFuzz